Python(pandas)でExcelファイルを読み込んでDataFrameにする
目次
準備
PandasでExcelファイル(xlsx)にアクセスするときに、openpyxlなどの外部モジュールが必要になります。 pipなどでインストールしてください。
read_excel関数
read_excel関数でExcelファイルを読み込んでDataFrameにします。
read_excel関数にはたくさんの引数があるのですが、まずは基本的な引数を設定して読み込んでみます。
read_excel関数で使用頻度が高そうな引数を抜粋して紹介します。
import pandas as pd
df = pd.read_excel(io, [sheet_name], [header], [names])
引数 |
型 |
内容 |
|---|---|---|
io |
strなど |
ファイル名、Excelオブジェクト、パスなど、読み込みたいExcelファイル。 |
sheet_name |
str, listなど |
読み込むシートの指定。規定値は0。シート番号を指定する場合はintで指定する。0始まりであることに注意。シート名をstrで指定することもできる。複数読み込むときはlistにシート番号かシート名を連ねて指定する。Noneを指定すると、シート名をキーにした辞書を返す。 |
header |
int, list |
ヘッダにする列の指定。規定値は0。 |
names |
array |
列名の指定。規定値はNone。 |
df |
DataFrame |
読み込んだ結果のDataFrame。 |
引数のうちioは必須です。ファイルを読み込む関数なのですから、どこから読み込むかを指定する必要があります。
その他の引数は任意です。
読み込み例
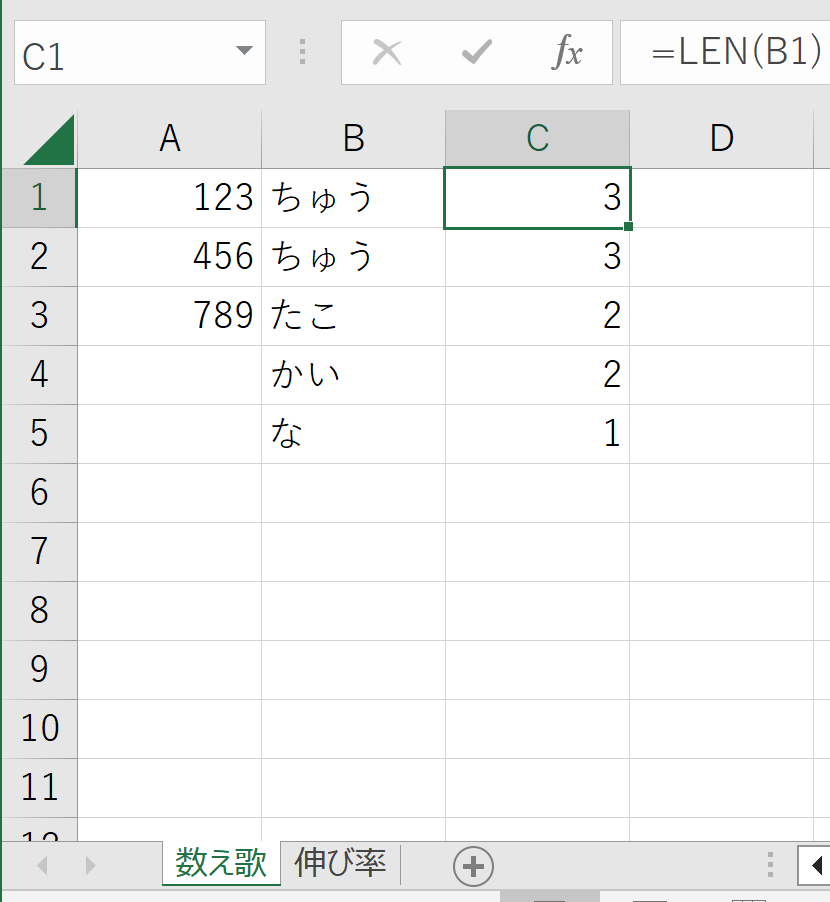
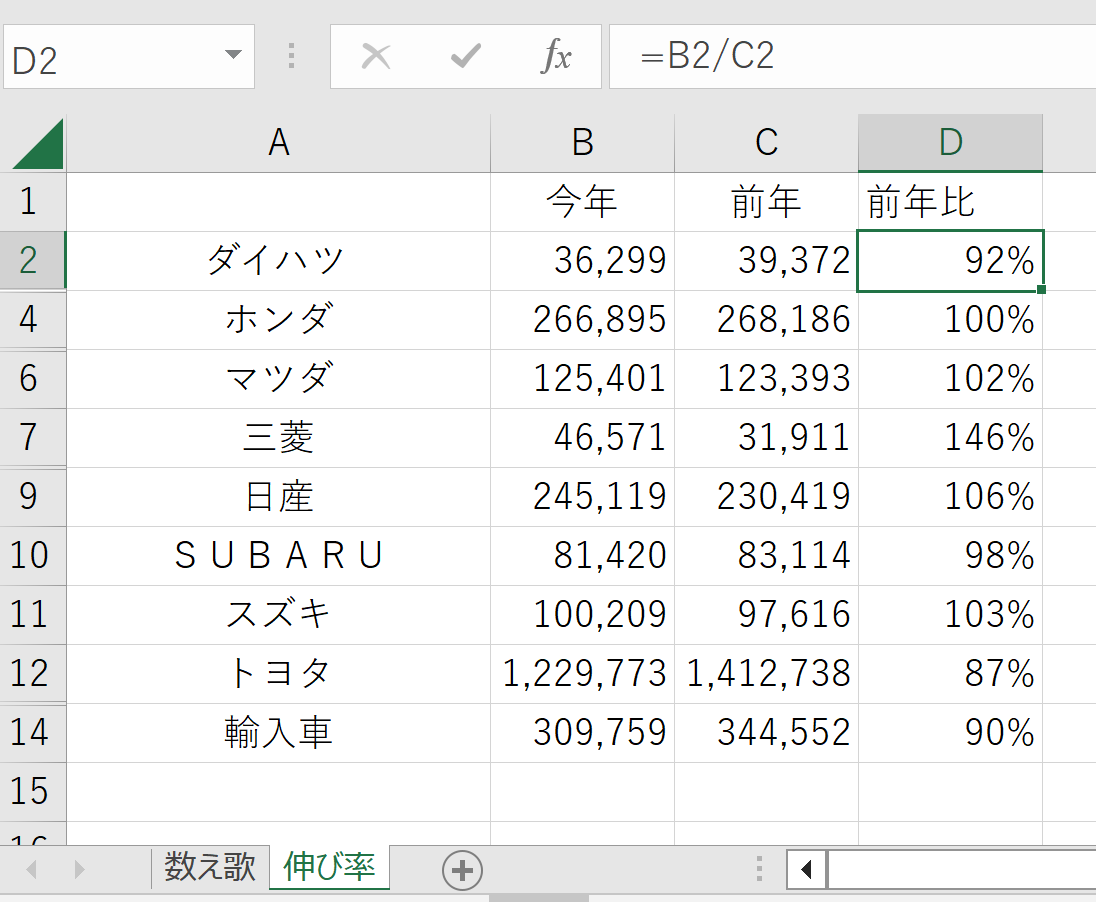
下図のような2つのシートを含むpandas_trial.xlsxという名前のxlsxファイルを作り、pandas.read_excel関数で読み込んでみます。
実行環境は、VisualStudioCode上のJupyter環境です。
ファイル名だけを指定して読み込む
ファイル名だけを引数に指定して読み込んでみます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx')
print(type(df))
df.head()
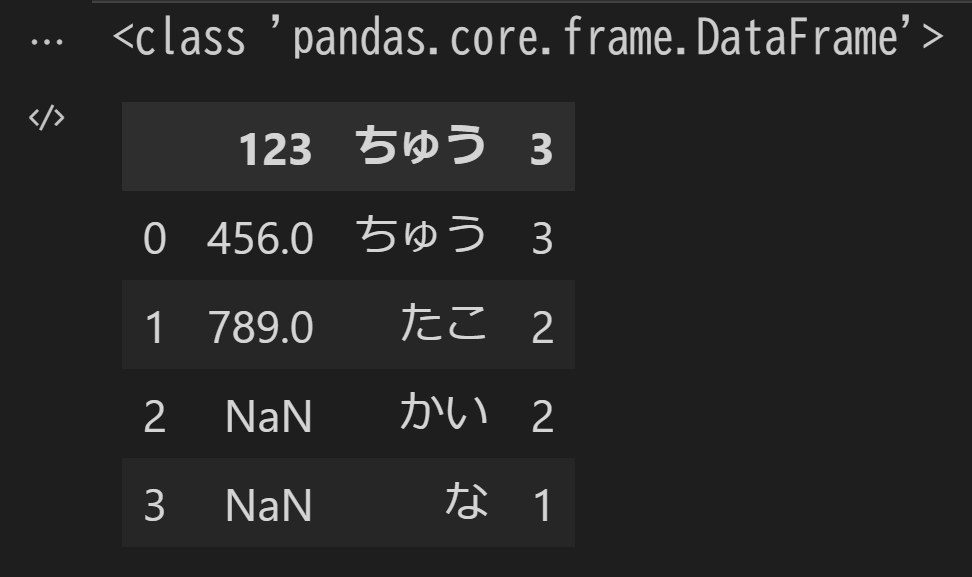
1つ目のシートの内容がDataFrameとして読み込まれました。
シートのC列には隣のセルの文字数をカウントするExcel関数が記載されているのですが、関数ではなくて計算結果が読み込まれました。
列のヘッダ行を指定する
読み込んだDataFrameを見てみると、Excelのシートの1行目が各列のヘッダになってしまいました。
header引数にNoneを指定して、ヘッダ行無しとして読み込んでみます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', header=None)
print(type(df))
df.head()
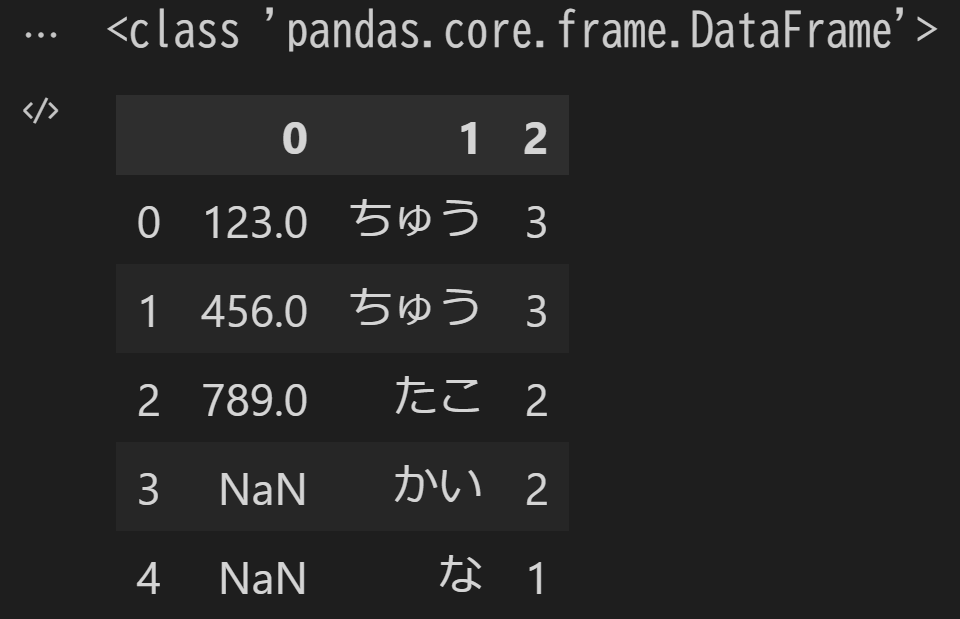
シートの1行目がデータとして読み込まれました。
ちなみに、header引数に数値を指定するとその行が列ヘッダとして読み込まれます。0始まりであることに注意してください。
シートの3行目(「たこ」の行)をヘッダとして読み込んでみます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', header=2)
print(type(df))
df.head()

列のヘッダの内容を指定する
各列のヘッダの表記が数字では味気ないので、names引数を使ってヘッダの内容を指定してみます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', header=None, names=['数字','文字','文字数'])
print(type(df))
df.head()
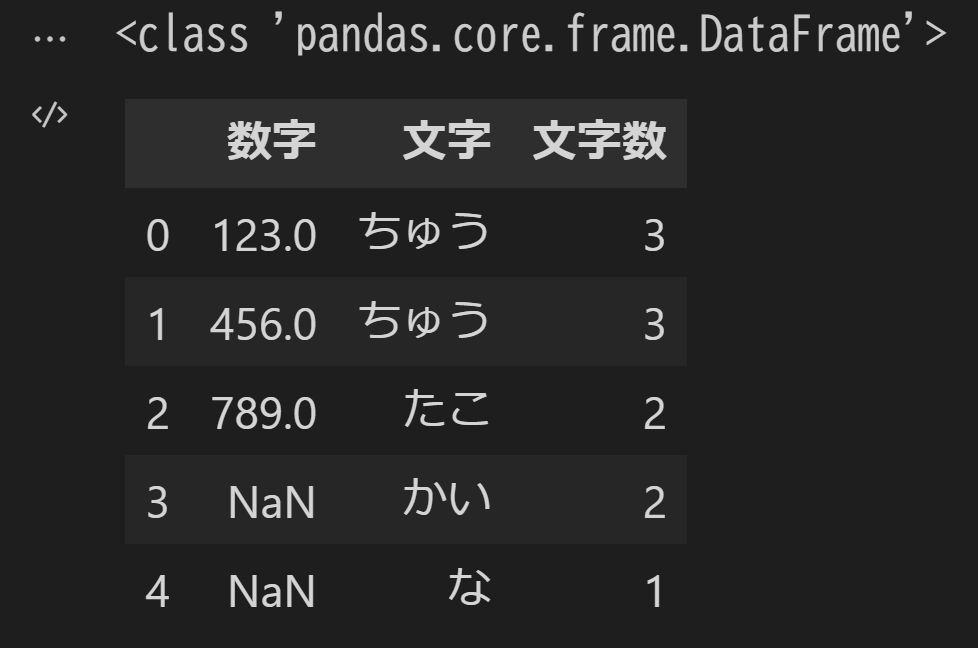
別のシートを読み込む
Excelファイルにはシートが2つ含まれていました。そこでsheet_name引数にシートの番号を指定して、2つ目のシートを読み込んでみます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', sheet_name=1, header=0)
print(type(df))
df.head()
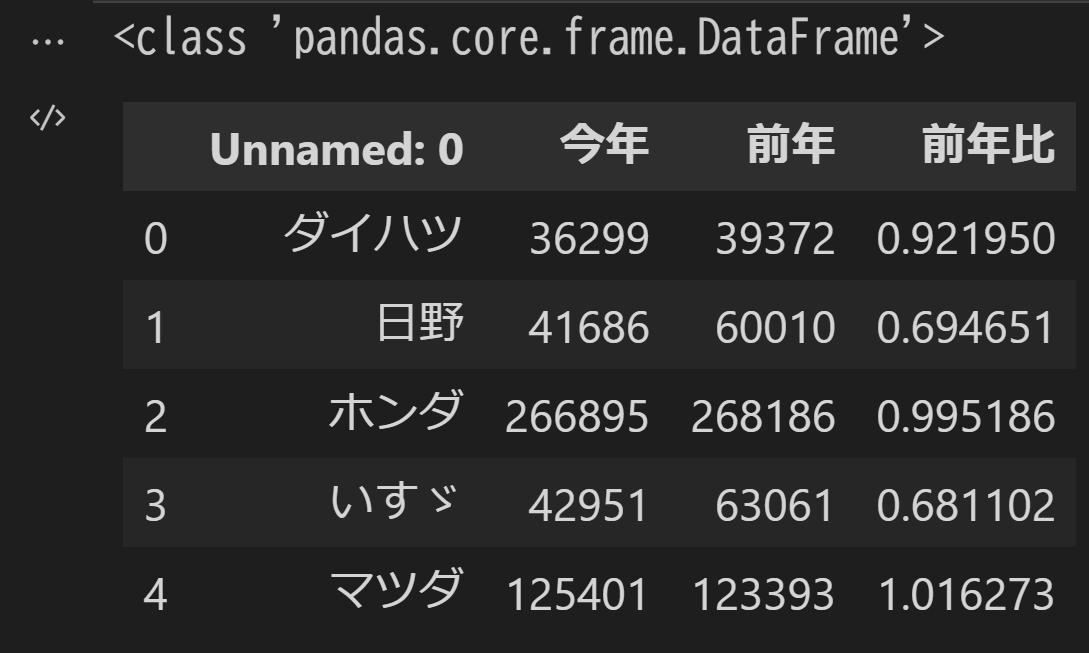
Excelのシートの番号は1から始まりますが、sheet_name引数に指定する場合は0から始まります。
実際にはシート番号よりもシート名で指定することが多いように思いますので、シート名で指定してみます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', sheet_name='伸び率', header=0)
print(type(df))
df.head()
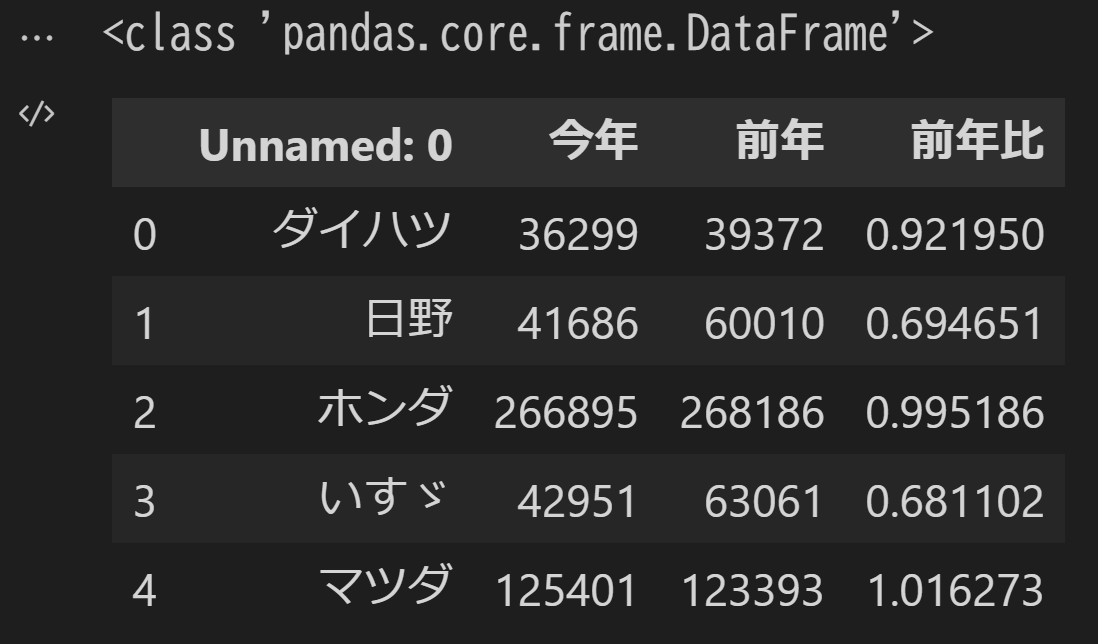
ところで、Excelでは非表示になっている「日野」や「いすゞ」も読み込まれていますね。
すべてのシートをまとめて読み込む
各シートごとに読み込むのではなくて、複数のシートをまとめて読み込んでみます。sheet_name引数のNoneを指定すると、すべてのシートを読み込みます。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', sheet_name=None)
print(type(df))
print(df.keys())
print(type(df['数え歌']))

sheet_nameにNoneを指定して全てのシートを読み込むと、read_excel関数の戻り値は辞書(dict)になります。Keyはシート名、Valueはそのシートを読み込んだDataFrameです。
複数のシートを読み込む
Excelファイル内の全てのシートを読み込む必要はないけれども複数のシートをまとめて読み込みたい場合は、sheet_name引数にシート番号かシート名のリストを渡します。
import pandas as pd
df = pd.read_excel('pandas_trial.xlsx', sheet_name=['伸び率','数え歌'])
print(type(df))
print(df.keys())
df
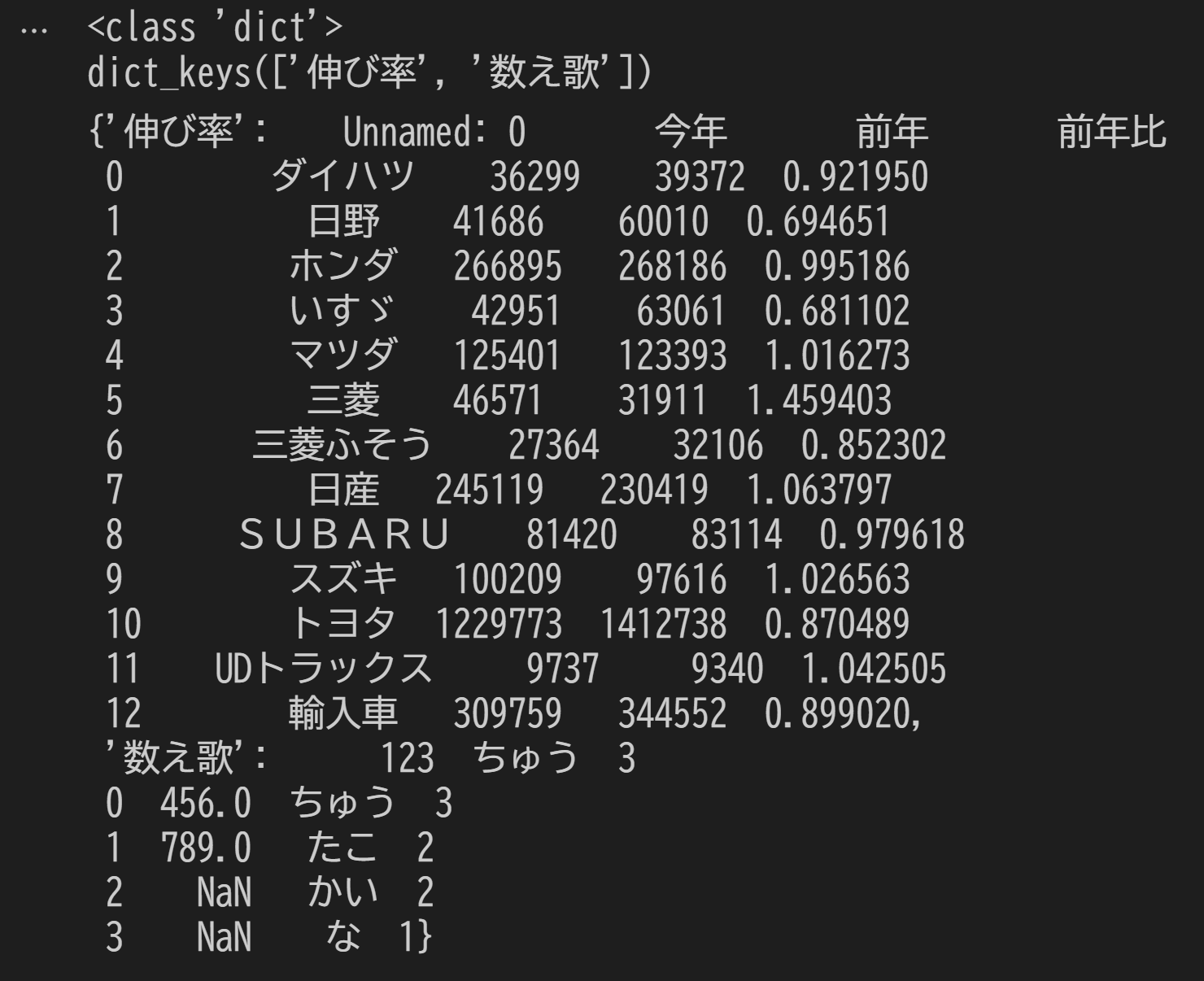
公開日
広告
Pythonでデータ分析カテゴリの投稿
- DataFrameの欠損値を特定の値で置き換える
- Pythonでpandas入門1(データの入力とデータへのアクセス)
- Pythonでpandas入門2(データの追加と削除および並び替え)
- Pythonでpandas入門3(データの統計量の計算)
- Pythonでpandas入門4(データの連結と結合)
- Pythonでpandas入門5(欠損値(NaN)の扱い)
- Pythonでデータを学習用と検証用に分割する
- Pythonでデータ分析入門1(初めての回帰分析)
- Pythonでデータ分析入門2(初めてのロジスティック回帰(2クラス分類))
- Pythonでデータ分析入門3(初めての決定木(多クラス分類))
- Pythonで回帰モデルの評価関数
- Pythonで箱ひげ図を描く
- Python(pandas)でExcelファイルを読み込んでDataFrameにする
- pandasでカテゴリ変数を数値データに変換する
- pandasでクロス集計する
- pandasで同じデータ(要素)がいくつあるか調べる
- pandasで相関係数を計算する
- pandasとseabornでデータの可視化(散布図行列)
- pandasの学習用のデータセットを入手する
- scikit-learnのサンプルデータセットを入手する