Pythonでデータ分析入門3(初めての決定木(多クラス分類))
Pythonで決定木を使った多クラス分類をします。
本投稿のコードは、Jupyter Notebook上で実行しています。コンソールで実行する場合は、適宜plotなどの表示用命令を追加してください。
目次
- 決定木とは
- 分析するデータ
- ライブラリのインポートとデータの読み込み
- データの確認
- データの分割
- モデルの学習をする
- 決定木を表示する
- 予測と精度の検証をする
- モデルの改善をする
- グリッドサーチでパラメータを自動探索する
決定木とは
目的変数に影響する説明変数の分割を、樹木状につなげたモデルです。
分類の用いる決定木を分類木、数値を求める決定木を回帰木と呼びます。
本投稿では、分類木を利用します。投稿内でグラフを描きますので、それを見ると決定木のイメージがしやすいと思います。
分析するデータ
seabornに備わっているirisというデータセットで試してみます。
界隈で有名な、アヤメの種類を寸法から分類するデータセットです。
列 |
内容 |
|---|---|
sepal_length |
萼片の長さ |
sepal_width |
萼片の幅 |
petal_length |
花弁の長さ |
petal_width |
花弁の幅 |
species |
花の品種(Setosa, Versicolor, Virginica) |
データセットには花の品種が3種類あります。萼片や花弁の情報から、花の品種を分類します。
ライブラリのインポートとデータの読み込み
pandasとseabornをインポートして、irisデータセットを読み込みます。
import pandas as pd
import seaborn as sns
df = sns.load_dataset('iris')
データの確認
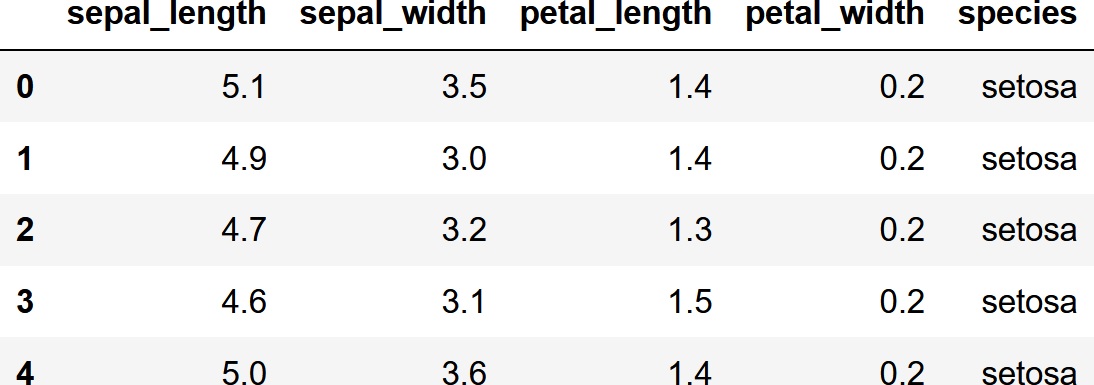
読み込んだデータの最初の5行と、データの情報を表示してみます。
df.head()
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
データ数は150件で、欠損値はありません。
seabornを使って散布図を表示してみます。品種で色分けをします。
import seaborn as sns
sns.pairplot(df, hue='species')

花弁で品種の分類ができそうです。
データの分割
データを学習用と検証用に分割します。検証用のデータは、学習したモデルの精度を確認するために使用します。
from sklearn.model_selection import train_test_split
X = df[['sepal_length','sepal_width','petal_length','petal_width']]
Y = df['species']
train_X, test_X, train_y, test_y = train_test_split(X, Y, test_size=0.3, random_state=0, stratify=Y)
train_Xが学習用の説明変数、test_Xが検証用の説明変数、train_yが学習用の目的変数、test_yが検証用の目的変数になります。
元データ数が150件で、検証用データの割合を30%に指定したので、学習用が105件で検証用が45件というふうに分割されます。
モデルの学習をする
決定木モデルで学習を行います。決定木には、Scikit-learnのDecisionTreeClassifierを使用します。
DecisionTreeClassifierクラスのオブジェクトを作って、そのfitメソッドに学習用の説明変数と目的変数(教師データ)を渡すと、モデルの学習が行われます。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth = 2, random_state = 0)
model.fit(train_X, train_y)
決定木の場合は、重要度の表示ができます。
print(pd.Series(model.feature_importances_, index=train_X.columns) )
sepal_length 0.0
sepal_width 0.0
petal_length 0.0
petal_width 1.0
dtype: float64
petal_widthが最重要のようです。前述の散布図やヒストグラムを見ると、さもありなんという感じです。
決定木を表示する
決定木をグラフにして表示してみます。
グラフの表示にはGraphVizという描画用ソフトウェアと、pydotplusというPythonからGraphVizを動かすためのモジュールを使用します。必要に応じて適宜インストールしてください。
from sklearn.tree import export_graphviz
export_graphviz(model, out_file="model.dot", feature_names=train_X.columns, class_names=['setosa','versicolor','virginica'], filled=True, rounded=True)
from matplotlib import pyplot as plt
from PIL import Image
import pydotplus
import io
graph = pydotplus.graph_from_dot_file(path="model.dot")
img_png = graph.create_png()
img = io.BytesIO(img_png)
img2 = Image.open(img)
plt.figure(figsize=(img2.width/100, img2.height/100), dpi=100)
plt.imshow(img2)
plt.axis("off")
plt.show()
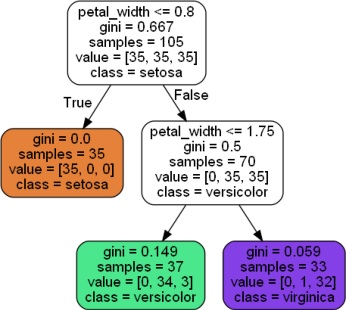
「petal_widthが0.8以下の場合はsetosa、petal_widthが0.8を超えて1.75以下の場合はversicolor、petal_widthが0.8を超えてさらに1.75を超える場合はvirginica」のように分類するモデルとなりました。分類にpetal_widthしか使っていないので、petal_widthだけ重要度が1なのですね。
予測と精度の検証をする
検証用説明変数による予測と、検証用目的変数との比較による精度の検証を行います。
まず予測を行います。
pred = model.predict(test_X)
print(pred)
['virginica' 'virginica' 'setosa' 'setosa' 'versicolor' 'setosa'
'versicolor' 'virginica' 'setosa' 'versicolor' 'setosa' 'virginica'
'setosa' 'virginica' 'versicolor' 'versicolor' 'versicolor' 'versicolor'
'versicolor' 'setosa' 'versicolor' 'virginica' 'setosa' 'versicolor'
'versicolor' 'virginica' 'virginica' 'virginica' 'versicolor' 'virginica'
'versicolor' 'setosa' 'setosa' 'versicolor' 'versicolor' 'virginica'
'versicolor' 'setosa' 'setosa' 'versicolor' 'setosa' 'virginica' 'setosa'
'setosa' 'virginica']
次にモデルの精度の計算を行います。
Scikit-learnにマクロ平均という多クラス分類の指標を計算する関数がありますので、それを利用します。
from sklearn.metrics import classification_report
print(classification_report(test_y, pred))
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.88 1.00 0.94 15
virginica 1.00 0.87 0.93 15
accuracy 0.96 45
macro avg 0.96 0.96 0.96 45
weighted avg 0.96 0.96 0.96 45
マクロ平均の精度が0.96なので、たぶん結構精度が高いと思います。
モデルの改善をする
決定木を深くすれば、精度が良くなるかもしれません。
そこで、決定木のmax_depthを10に設定して学習し直してみます。
model = DecisionTreeClassifier(max_depth = 10, random_state = 0 )
model.fit(train_X, train_y)
pred = model.predict(test_X)
print(classification_report(test_y, pred))
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.94 1.00 0.97 15
virginica 1.00 0.93 0.97 15
accuracy 0.98 45
macro avg 0.98 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
少し良くなりました。
グリッドサーチでパラメータを自動探索する
前述の改善では決定木の深さを10にしてみましたが、これを手でいちいち計算するのは面倒です。そこで、グリッドサーチという手法で自動的にパラメータを探索してみます。
グリッドサーチをする際は、パラメータを指定しないでオブジェクトを作ります。
グリッドサーチ用のGridSearchCVオブジェクトに、モデルとパラメータのパターンを渡します。cv引数は、交差検証の分割数を指定します。
model = DecisionTreeClassifier(random_state = 0)
from sklearn.model_selection import GridSearchCV
params = {'max_depth':[2,3,4,5,6,7,8,9,10]}
search = GridSearchCV(model, params, cv=2, return_train_score=True)
search.fit(train_X,train_y)
print(search.best_params_)
{'max_depth': 5}
max_depthの最適なパラメータは5という結果になりました。
交差検証した際の、学習データによる予測の結果と検証データによる予測の結果を、パラメータ毎に表示してみます。
train_score = search.cv_results_["mean_train_score"]
test_score = search.cv_results_["mean_test_score"]
from matplotlib import pyplot as plt
plt.plot([2,3,4,5,6,7,8,9,10], train_score, label="train_score")
plt.plot([2,3,4,5,6,7,8,9,10], test_score, label="test_score")
plt.title('train_score vs test_score')
plt.xlabel('max_depth')
plt.legend()
plt.show()
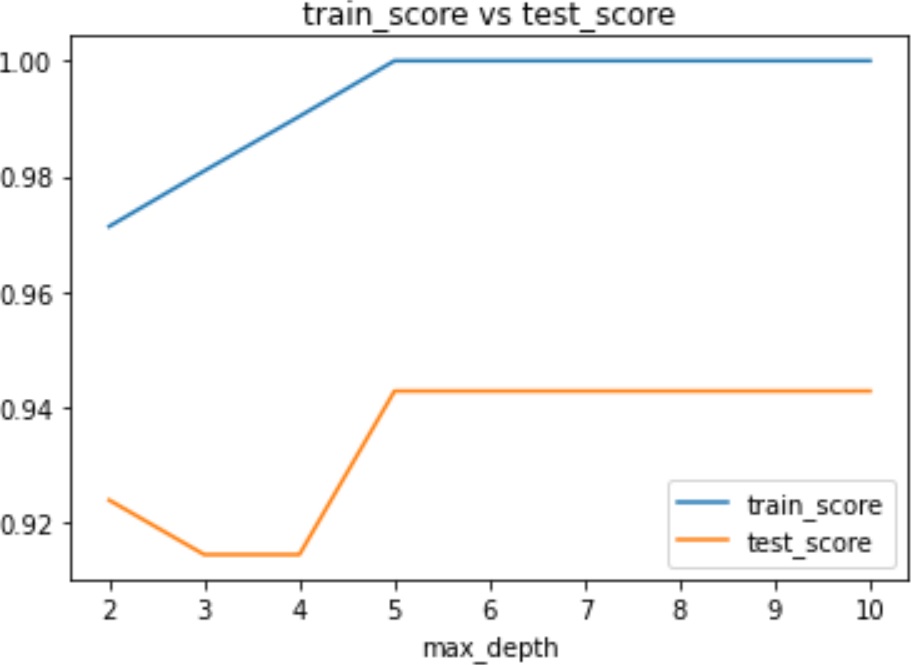
max_depthが5より大きくなると、精度が変化しなくなりますね。
では、このモデルの精度を計算してみます。
max_depthを指定し直して学習し直さなくても、グリッドサーチのオブジェクトからベストなパラメータのモデルを取り出して利用できます。
model = search.best_estimator_
pred = model.predict(test_X)
print(classification_report(test_y, pred))
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.94 1.00 0.97 15
virginica 1.00 0.93 0.97 15
accuracy 0.98 45
macro avg 0.98 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
このモデルの決定木をグラフで表示してみます。
export_graphviz(model, out_file="model.dot", feature_names=train_X.columns, class_names=['setosa','versicolor','virginica'], filled=True, rounded=True)
graph = pydotplus.graph_from_dot_file(path="model.dot")
img_png = graph.create_png()
img = io.BytesIO(img_png)
img2 = Image.open(img)
plt.figure(figsize=(img2.width/100, img2.height/100), dpi=100)
plt.imshow(img2)
plt.axis("off")
plt.show()
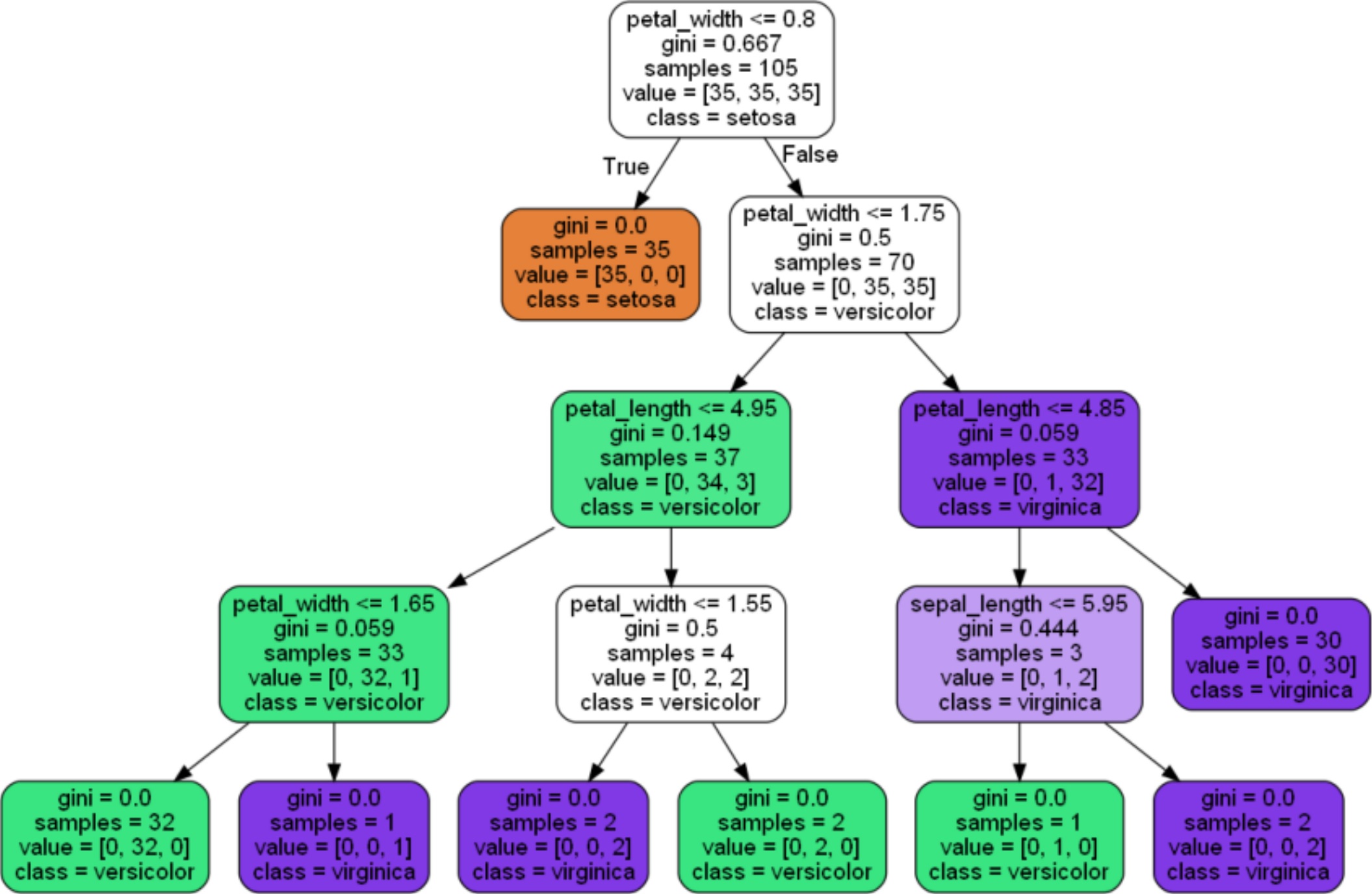
これで、萼片と花弁の大きさから品種を分類する決定木モデルが作成できました。
公開日
広告
Pythonでデータ分析カテゴリの投稿
- DataFrameの欠損値を特定の値で置き換える
- Pythonでpandas入門1(データの入力とデータへのアクセス)
- Pythonでpandas入門2(データの追加と削除および並び替え)
- Pythonでpandas入門3(データの統計量の計算)
- Pythonでpandas入門4(データの連結と結合)
- Pythonでpandas入門5(欠損値(NaN)の扱い)
- Pythonでデータを学習用と検証用に分割する
- Pythonでデータ分析入門1(初めての回帰分析)
- Pythonでデータ分析入門2(初めてのロジスティック回帰(2クラス分類))
- Pythonでデータ分析入門3(初めての決定木(多クラス分類))
- Pythonで回帰モデルの評価関数
- Pythonで箱ひげ図を描く
- Python(pandas)でExcelファイルを読み込んでDataFrameにする
- pandasでカテゴリ変数を数値データに変換する
- pandasでクロス集計する
- pandasで同じデータ(要素)がいくつあるか調べる
- pandasで相関係数を計算する
- pandasとseabornでデータの可視化(散布図行列)
- pandasの学習用のデータセットを入手する
- scikit-learnのサンプルデータセットを入手する