Pythonでpandas入門1(データの入力とデータへのアクセス)
Pythonのデータ分析で用いられるpandasの入門編です。データの入力と、入力されたデータから必要な部分の取り出しについて解説します。
目次
pandasのインポート
pandasをインポートする際には、一般的にpdという名前でインポートします。
import pandas as pd
pandasのデータ構造
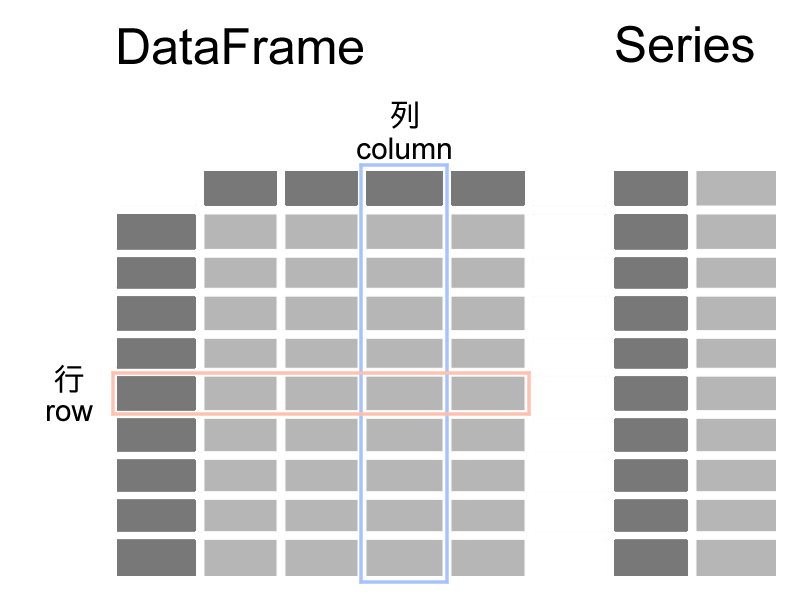
pandasで使用するデータの構造として、DataFrameとSeriesというものがあります。
DataFrameは2次元の表のようなものです。縦のデータの集まりを列(column)、横の列の集まりを行(row)と言います。Excelのスプレッドシートのようなイメージです。各要素には、文字列や数値などを格納できます。
Seriesは、DataFrameの列を取り出したものです。
DataFrameの生成
DataFrameはDataFrameコンストラクタに、Keyを列名、Valueをデータとした辞書を指定して作成できます。
import pandas as pd
df = pd.DataFrame(
{
"Name": [
"Windows",
"OS X",
"Chrome OS",
"Linux",
],
"World": [75.56, 16.48, 2.09, 1.97],
"Japan": [65.88, 16.64, 0.51, 1.34],
}
)
print(type(df))
print(df)
print(type(df['World']))
実行するとこうなります。
<class 'pandas.core.frame.DataFrame'>
Name World Japan
0 Windows 75.56 65.88
1 OS X 16.48 16.64
2 Chrome OS 2.09 0.51
3 Linux 1.97 1.34
<class 'pandas.core.series.Series'>
オブジェクトのタイプがDataFrameに、DaraFrameから切り出した列がSeriesになっています。
各行の一番左に0から始まる番号が割り振られています。これは各行(row)のインデックスです。
Seriesの生成
Seriesを作るには、DataFrameから切り出しても良いのですが、Seriesコンストラクタの引数にリストを指定することでSeriesオブジェクトを生成できます。
import pandas as pd
s = pd.Series([75.56, 16.48, 2.09, 1.97], name='World')
print(type(s))
print(s)
実行するとこうなります。
<class 'pandas.core.series.Series'>
0 75.56
1 16.48
2 2.09
3 1.97
Name: World, dtype: float64
Seriesにも各行にインデックスが付きます。
CSVファイルの読み取り
CSVファイルを読み込むには、read_csv()メソッドを使用します。
例えば、下記のようなCSVファイルがあるとします。
Name,World,Japan
Windows,75.56,65.88
OS X,16.48,16.64
Chrome OS,2.09,0.51
Linux,1.97,1.34
これを読み込んでDataFrameにします。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df)
CSVファイル内で日本語が使用されている場合は、エンコードを指定しないと文字化けする場合があります。多くはshift_jisかutf-8のどちらかです。
Name World Japan
0 Windows 75.56 65.88
1 OS X 16.48 16.64
2 Chrome OS 2.09 0.51
3 Linux 1.97 1.34
DataFrameの情報を取得する
DataFrameのshapeプロパティで、行と列の数を取得できます。
DataFrameのindexプロパティでインデックスの情報を取得し、len()でその長さを計ると行数を取得できます。
DataFrameのcolumnsプロパティで列名のリストを取得し、len()でその長さを計ると列数を取得できます。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df)
print(df.shape)
print(df.index)
print(len(df.index))
print(df.columns)
print(len(df.columns))
出力はこうなります。
Name World Japan
0 Windows 75.56 65.88
1 OS X 16.48 16.64
2 Chrome OS 2.09 0.51
3 Linux 1.97 1.34
(4, 3)
RangeIndex(start=0, stop=4, step=1)
4
Index(['Name', 'World', 'Japan'], dtype='object')
3
データの参照
print()でDataFrameを表示できますが、他にもいくつか表示する方法があります。
先頭または末尾の行を表示する
head(n)でデータの先頭n行分を、tail(n)でデータ末尾n行分を表示できます。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df.head(2))
print(df.tail(2))
下記のように出力されます。
Name World Japan
0 Windows 75.56 65.88
1 OS X 16.48 16.64
Name World Japan
2 Chrome OS 2.09 0.51
3 Linux 1.97 1.34
大きいデータの確認をする際に便利です。
特定の行を取得する
スライスを使って、特定の行を取得できます。
インデックスが1から2の行を取り出すには、下記のようにします。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df[1:3])
終端のインデックスの指定が2ではなく2+1であることに注意です。
Name World Japan
1 OS X 16.48 16.64
2 Chrome OS 2.09 0.51
特定の列を取得する
列名を指定して、特定の列を取得できます。負数の列を取得する場合は、リストを指定します。
Japan列を取り出す場合と、Name列とJapan列を取り出す場合の例です。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df['Japan'])
print(df[['Name','Japan']])
複数行を指定する場合は[]の中にリストで指定することに注意です。
0 65.88
1 16.64
2 0.51
3 1.34
Name: Japan, dtype: float64
Name Japan
0 Windows 65.88
1 OS X 16.64
2 Chrome OS 0.51
3 Linux 1.34
特定の列の特定の行を取得する
上記を組み合わせてみます。
Name列とJapan列の、インデックス1~2のデータを取得してみます。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df[['Name','Japan']][1:3])
下記のように出力されます。
Name Japan
1 OS X 16.64
2 Chrome OS 0.51
DetaFrame内の位置を指定してデータを取得する
ilocプロパティを使って位置を指定してデータを取得します。iloc[n]でn行目のデータを、iloc[:,n]でn列目のデータを、iloc[m,n]でm行n列のデータを取得できます。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df.iloc[3])
print(df.iloc[:,2])
print(df.iloc[0,2])
iloc[3]で3行目のデータを取得した場合は、列名とデータのSeriesになっています。
Name Linux
World 1.97
Japan 1.34
Name: 3, dtype: object
0 65.88
1 16.64
2 0.51
3 1.34
Name: Japan, dtype: float64
65.88
行ラベルや列ラベルを指定してデータを取得する
locプロパティを使って、ラベルを指定してデータを取得します。複数のラベルを指定する場合は、ラベルのリストで指定します。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df.loc[3])
print(df.loc[:,['Name','Japan']])
print(df.loc[0,'Japan'])
Name Linux
World 1.97
Japan 1.34
Name: 3, dtype: object
Name Japan
0 Windows 65.88
1 OS X 16.64
2 Chrome OS 0.51
3 Linux 1.34
65.88
条件を付けてデータを取り出す
指定した行の値が条件を満たす行だけを取り出すことができます。
ブール演算を使って複数の条件式を指定することもできます。ただし、and、or、notの代わりに&、|、~を使用します。
import pandas as pd
df = pd.read_csv('test.csv', encoding='shift_jis')
print(df)
print(df[(df['World'] > 2.0) & (df['Japan'] < 50.0)])
条件式を括弧で括っていることに注意してください。
Name World Japan
0 Windows 75.56 65.88
1 OS X 16.48 16.64
2 Chrome OS 2.09 0.51
3 Linux 1.97 1.34
Name World Japan
1 OS X 16.48 16.64
2 Chrome OS 2.09 0.51
公開日
広告
Pythonでデータ分析カテゴリの投稿
- DataFrameの欠損値を特定の値で置き換える
- Pythonでpandas入門1(データの入力とデータへのアクセス)
- Pythonでpandas入門2(データの追加と削除および並び替え)
- Pythonでpandas入門3(データの統計量の計算)
- Pythonでpandas入門4(データの連結と結合)
- Pythonでpandas入門5(欠損値(NaN)の扱い)
- Pythonでデータを学習用と検証用に分割する
- Pythonでデータ分析入門1(初めての回帰分析)
- Pythonでデータ分析入門2(初めてのロジスティック回帰(2クラス分類))
- Pythonでデータ分析入門3(初めての決定木(多クラス分類))
- Pythonで回帰モデルの評価関数
- Pythonで箱ひげ図を描く
- Python(pandas)でExcelファイルを読み込んでDataFrameにする
- pandasでカテゴリ変数を数値データに変換する
- pandasでクロス集計する
- pandasで同じデータ(要素)がいくつあるか調べる
- pandasで相関係数を計算する
- pandasとseabornでデータの可視化(散布図行列)
- pandasの学習用のデータセットを入手する
- scikit-learnのサンプルデータセットを入手する