pandasでクロス集計する
Pythonでpandasを使ってクロス集計をします。
本投稿のコードは、Jupyter Notebook上で実行しています。コンソールで実行する場合は、適宜plotなどの表示用命令を追加してください。
目次
- クロス集計とは
- サンプルデータ
- crosstab関数でクロス集計する
- tipsデータをクロス集計する
- データの複数の列でグループ分けしてクロス集計する
- 各列各行の合計を計算する
- 集計結果を正規化する
- 集計結果を可視化する
- 数値データをクロス集計してみる
クロス集計とは
いくつかのカテゴリに属するデータを、それぞれのカテゴリで同時に分類してその度数を集計することを、クロス集計と呼びます。
2つのカテゴリを縦軸と横軸にならべて、各データがどのカテゴリの組み合わせに属するのかをマトリクスにまとめるようなイメージです。実際にはカテゴリは3つ以上の場合もあります。
サンプルデータ
seabornのtipsというサンプルデータセットでクロス集計を試してみます。
このデータセットは、あるレストランでどういう属性の人がいくらチップを支払ったかというテーブルデータです。
列 |
型 |
内容 |
|---|---|---|
total_bill |
float64 |
総支払額 |
tip |
float64 |
チップの額 |
sex |
category |
性別 |
smoker |
category |
喫煙者かどうか |
day |
category |
曜日 |
time |
category |
ランチかディナーか |
size |
int64 |
人数 |
データの入手と内容の確認
データのダウンロード方法については、こちらを参照してください。
import pandas as pd
import seaborn as sns
df = sns.load_dataset('tips')
データの情報を見てみます。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KB
df.head()
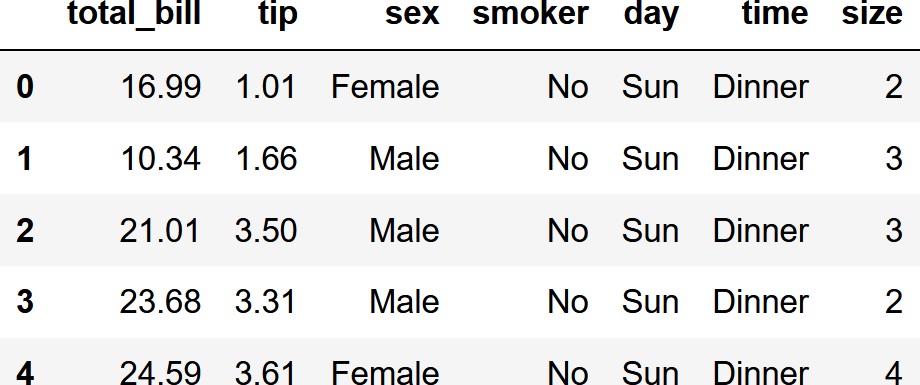
crosstab関数でクロス集計する
pandasのcrosstab関数で、クロス集計を行います。
import pandas as pd
ret = pd.crosstab(index, columns, [values], [rownames], [colnames], [aggfunc], [margins], [margins_name], [dropna], [normalize])
変数 |
型 |
内容 |
|---|---|---|
index |
array,Series,list |
行の側でグループ分けするデータ。 |
columns |
array,Series,list |
列の側でグループ分けするデータ。 |
values |
array |
省略可。規定値はNone。 |
rownames |
sequence |
省略可。規定値はNone。各行の名前。 |
colnames |
sequence |
省略可。規定値はNone。各列の名前。 |
aggfunc |
function |
省略可。規定値はNone。 |
margins |
bool |
省略可。規定値はFalse。各行、各列の合計を集計するか。 |
margins_name |
str |
省略可。規定値はAll。合計の行および列の名前。 |
dropna |
bool |
省略可。規定値はTrue。欠損値を除外するか。 |
normalize |
bool,str |
省略可。規定値はFalse。正規化するか。 |
ret |
DataFrame |
クロス集計結果の表。 |
normalizeはTrue/Falseのブール値の他に、all、index、columnsのいずれかを指定できます。
False |
集計結果を正規化しない |
Trueまたはall |
全ての集計結果を使って正規化する |
index |
各行の集計結果をそれぞれ正規化する |
columns |
各列の集計結果をそれぞれ正規化する |
tipsデータをクロス集計する
ではクロス集計を試してみます。
男女別に喫煙者がどれくらいいるのか集計します。
pd.crosstab(df['sex'], df['smoker'])
index引数にsex列を、columns引数にsmoker列を渡しました。集計結果の表はこうなります。
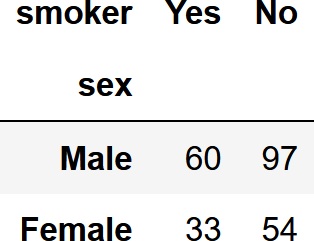
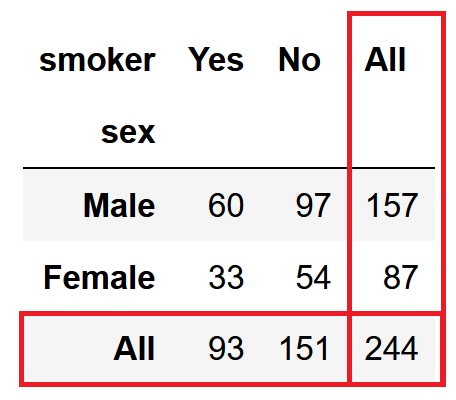
男性の喫煙者が60名居たということですね。
データの複数の列でグループ分けしてクロス集計する
グループ分けする列を複数指定してクロス集計してみます。
各曜日のランチとディナーの、男女別の数を集計します。
crosstab関数columns引数に、Seriesのリストを指定します。
pd.crosstab(df['sex'],[df['day'],df['time']])
下表のように列側に複数のカテゴリが表示されます。
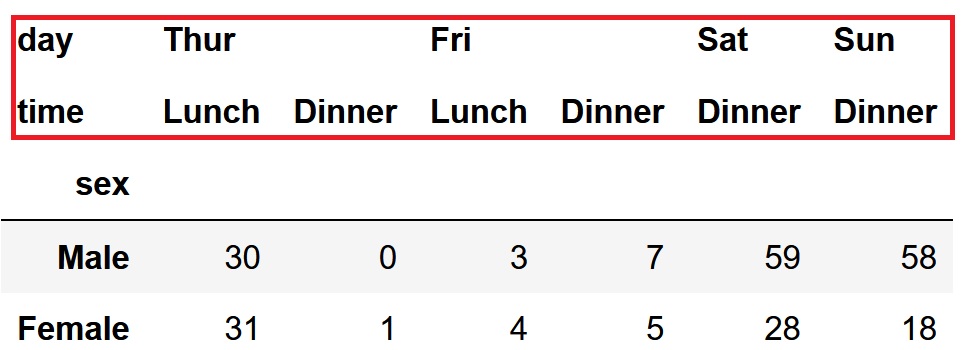
index引数にSeriesのリストを渡すと、列側に複数のカテゴリを指定できます。
pd.crosstab([df['sex'], df['smoker']],df['time'])
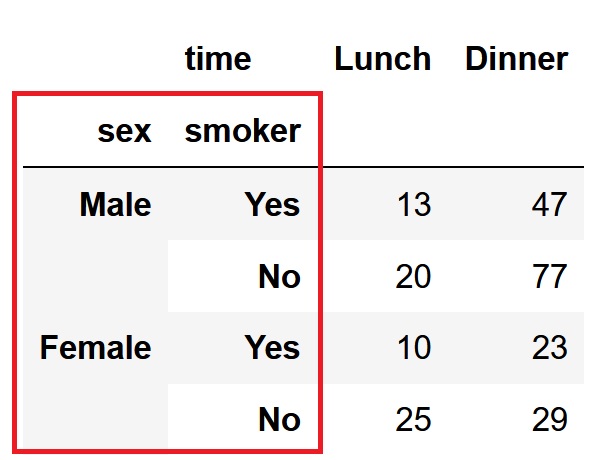
index引数とcolumns引数に、同時にSeriesのリストを指定することもできます。
pd.crosstab([df['sex'], df['smoker']],[df['day'],df['time']])
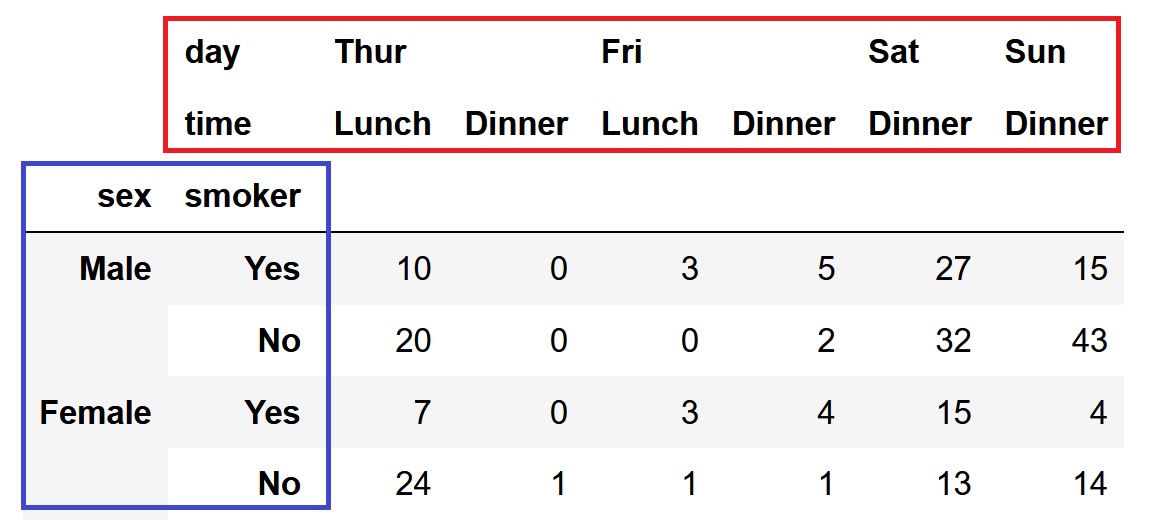
各列各行の合計を計算する
margins引数をTrueにすると、各列毎、各行毎の合計を計算して、クロス集計表に追加することができます。
pd.crosstab(df['sex'], df['smoker'], margins=True)
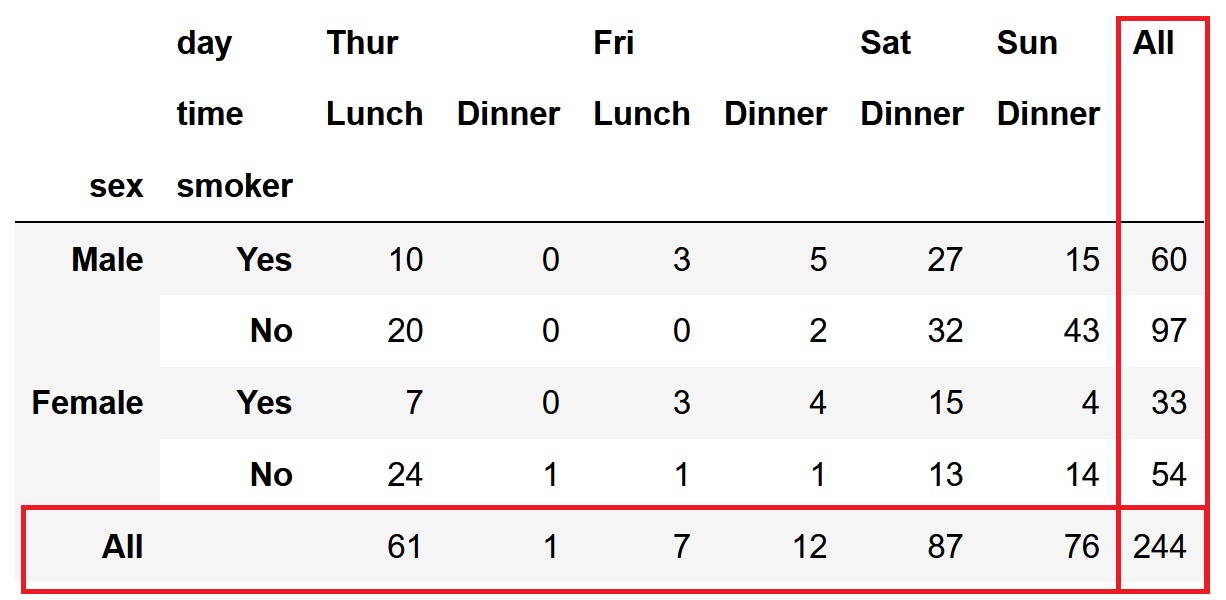
複数のカテゴリで集計した場合でも、同様に各列毎、各行毎の合計を追加できます。
pd.crosstab([df['sex'], df['smoker']], [df['day'], df['time']], margins=True)
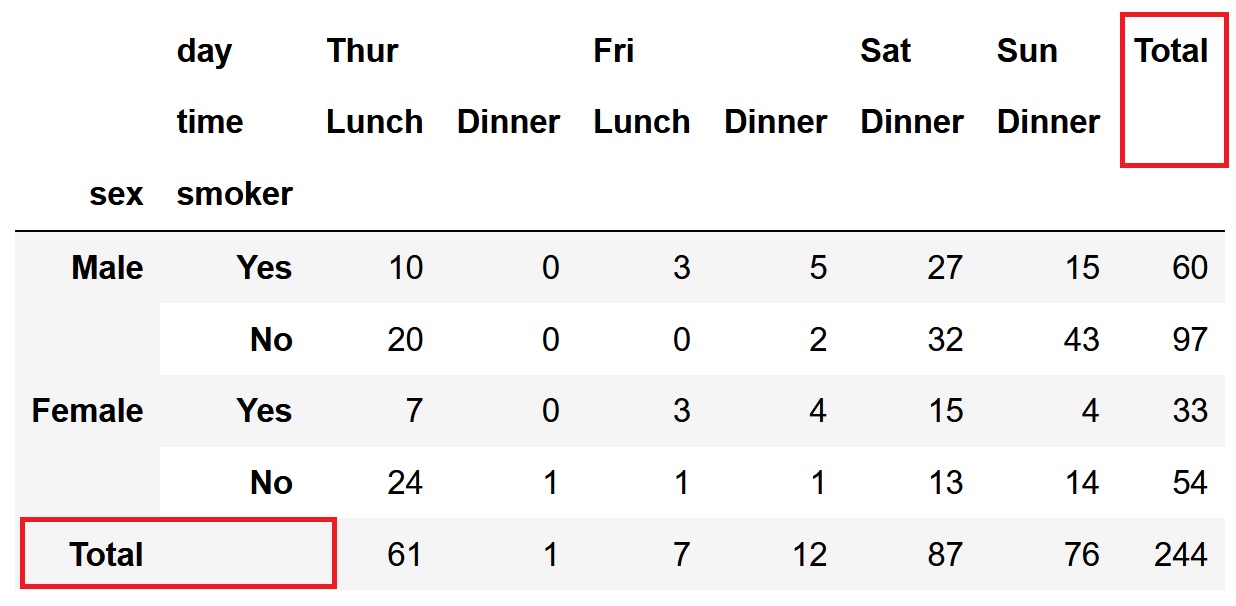
合計部分の列および行の名前の既定値はAllですが、margins_name引数に文字列を指定することで、名前を変更することができます。
pd.crosstab([df['sex'], df['smoker']], [df['day'], df['time']], margins=True, margins_name='Total')
集計結果を正規化する
normalize引数にallなどの文字列を指定することで、集計結果を正規化できます。
pd.crosstab(df['sex'], df['smoker'], normalize='all')
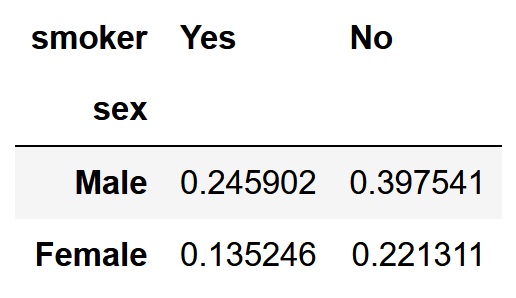
合計の計算を行う場合は、合計の列および行についても正規化されます。正規化された全合計値は1になります。
pd.crosstab(df['sex'], df['smoker'], margins=True, normalize='all')
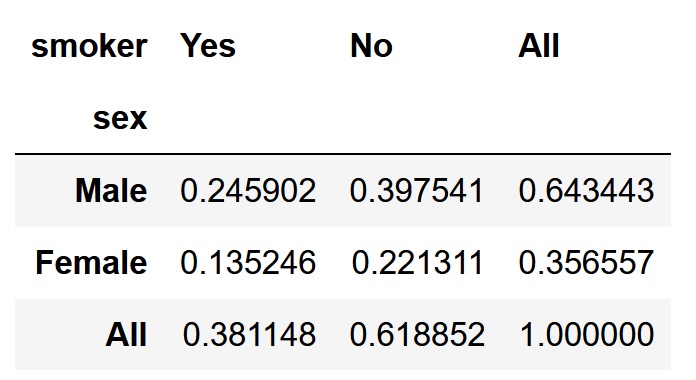
normalize引数にindexと指定すると、各行毎に正規化が行われます。
pd.crosstab(df['sex'], df['smoker'], margins=True, normalize='index')

normalize引数にcolumnsと指定すると、各列毎に正規化が行われます。
pd.crosstab(df['sex'], df['smoker'], margins=True, normalize='columns')
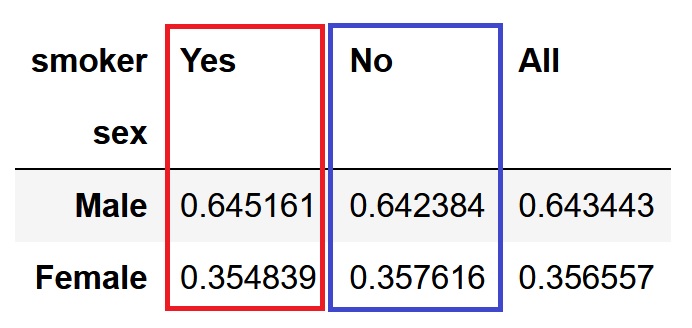
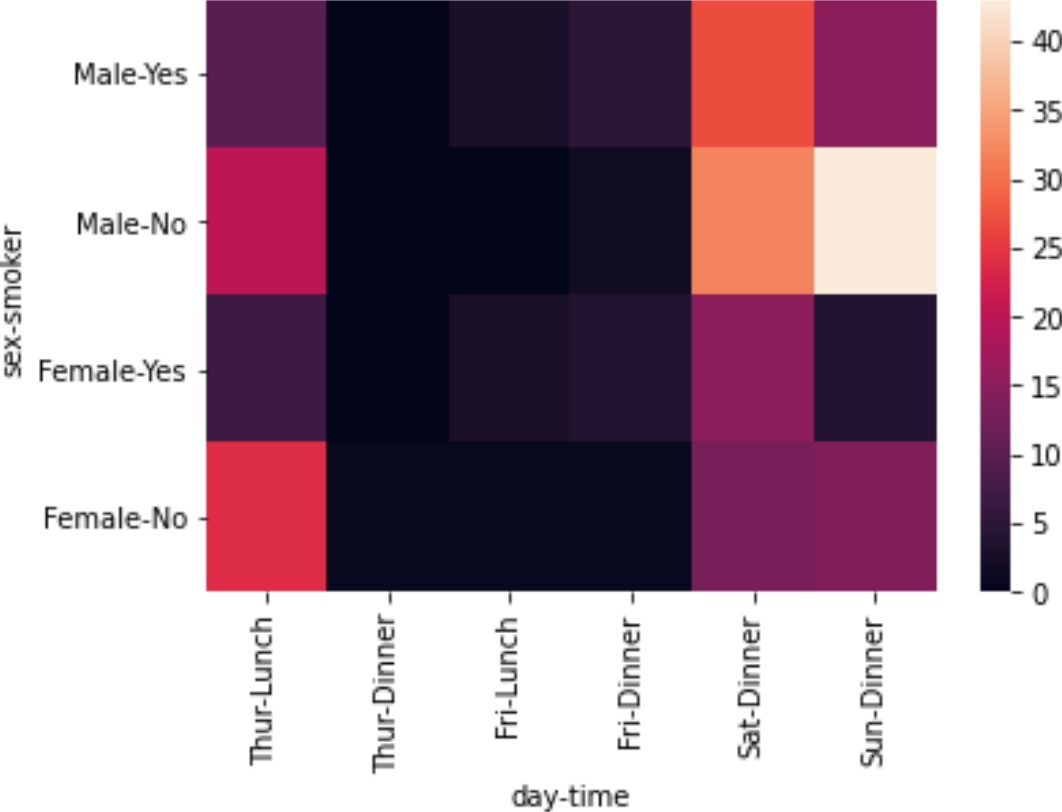
集計結果を可視化する
集計結果をヒートマップで可視化してみます。可視化にはseabornを使用します。
crosstab関数の戻り値はDataFrameです。seabornのheatmap関数にこのDataFrameを渡すと、ヒートマップとして描画します。Jupyter Notebook環境であればそのままグラフが表示されます。heatmap関数はAxesSubplotオブジェクトを返すので、コンソールなどの環境ではpyplot.show()などで描画します。
import seaborn as sns
sns.heatmap(pd.crosstab(df['sex'],df['smoker']))
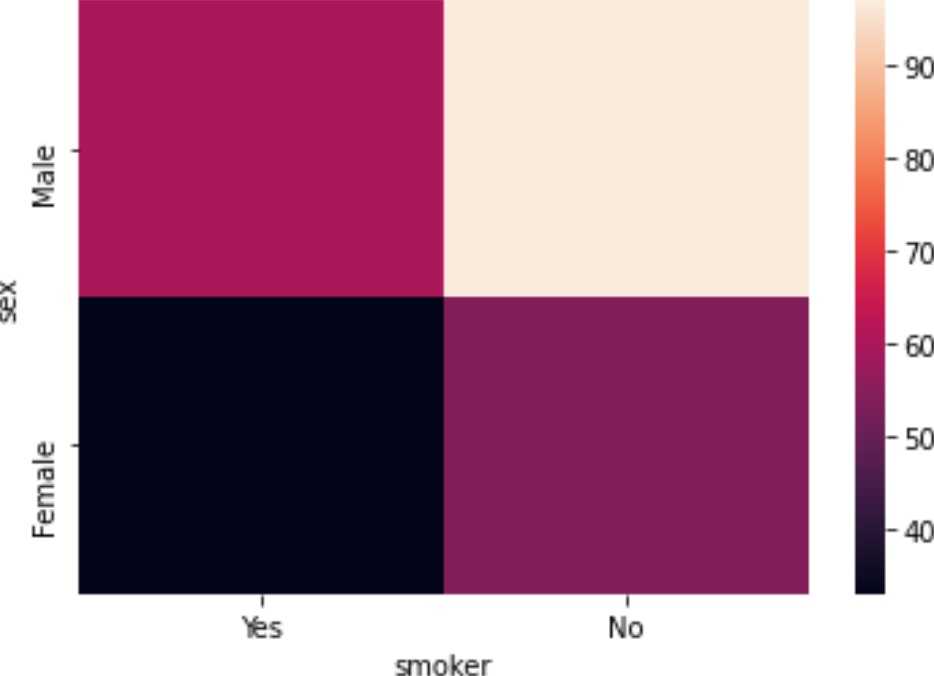
sns.heatmap(pd.crosstab([df['sex'],df['smoker']],[df['day'],df['time']]))
数値データをクロス集計してみる
クロス集計はカテゴリデータに対して行うもので、数値データに向くものではありません。ですが、試しに数値データをクロス集計してみます。
pd.crosstab(df['sex'],df['total_bill'])

上記は、縦軸を男女別にして、横軸を支払額にした、クロス集計です。これではあまり役にはたちませんね。
そこで、total_bill列をビニングしてみます。
bins_total_bill = [0,20,40,60]
df_cut, bin_indice = pd.cut(df['total_bill'], bins=bins_total_bill, retbins=True, labels=['0-20','20-40','40-60'])
pd.crosstab(df_cut,df['sex'])
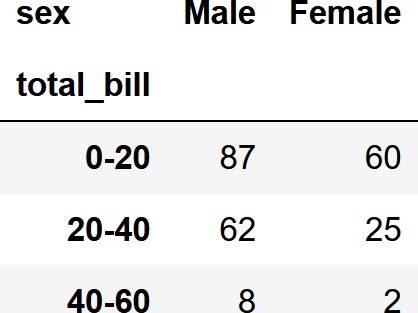
公開日
広告
Pythonでデータ分析カテゴリの投稿
- DataFrameの欠損値を特定の値で置き換える
- Pythonでpandas入門1(データの入力とデータへのアクセス)
- Pythonでpandas入門2(データの追加と削除および並び替え)
- Pythonでpandas入門3(データの統計量の計算)
- Pythonでpandas入門4(データの連結と結合)
- Pythonでpandas入門5(欠損値(NaN)の扱い)
- Pythonでデータを学習用と検証用に分割する
- Pythonでデータ分析入門1(初めての回帰分析)
- Pythonでデータ分析入門2(初めてのロジスティック回帰(2クラス分類))
- Pythonでデータ分析入門3(初めての決定木(多クラス分類))
- Pythonで回帰モデルの評価関数
- Pythonで箱ひげ図を描く
- Python(pandas)でExcelファイルを読み込んでDataFrameにする
- pandasでカテゴリ変数を数値データに変換する
- pandasでクロス集計する
- pandasで同じデータ(要素)がいくつあるか調べる
- pandasで相関係数を計算する
- pandasとseabornでデータの可視化(散布図行列)
- pandasの学習用のデータセットを入手する
- scikit-learnのサンプルデータセットを入手する