pandasで相関係数を計算する
pandasのDataFrameの各項目間の相関係数を計算してみます。
目次
サンプル
seabornでダウンロードできるdiamondsデータセットを使用します。
import pandas as pd
import seaborn as sns
df = sns.load_dataset('diamonds')
print(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 53940 entries, 0 to 53939
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 carat 53940 non-null float64
1 cut 53940 non-null category
2 color 53940 non-null category
3 clarity 53940 non-null category
4 depth 53940 non-null float64
5 table 53940 non-null float64
6 price 53940 non-null int64
7 x 53940 non-null float64
8 y 53940 non-null float64
9 z 53940 non-null float64
dtypes: category(3), float64(6), int64(1)
memory usage: 3.0 MB
None
データの中身は下表の通りです。
項目 |
内容 |
|---|---|
carat |
重さ。 |
cut |
カットの品質。(Fair、Good、Very Good、Premium、Ideal) |
color |
色。J(悪)~D (良) |
clarity |
透明度。I1(悪)、SI2、SI1、VS2、VS1、VVS2、VVS1、IF(良) |
depth |
相対的な厚さ。 |
table |
天面の大きさ。 |
price |
価格。USドル |
x |
長さ。 mm |
y |
幅。 mm |
z |
厚さ。 mm |
相関係数を計算してみる
DataFrameのcorrメソッドで、各数値項目間の相関係数を計算できます。オプション指定しない場合は、ピアソンの相関係数が計算されます。
import pandas as pd
import seaborn as sns
df = sns.load_dataset('diamonds')
print(df.corr())
carat depth table price x y z
carat 1.000000 0.028224 0.181618 0.921591 0.975094 0.951722 0.953387
depth 0.028224 1.000000 -0.295779 -0.010647 -0.025289 -0.029341 0.094924
table 0.181618 -0.295779 1.000000 0.127134 0.195344 0.183760 0.150929
price 0.921591 -0.010647 0.127134 1.000000 0.884435 0.865421 0.861249
x 0.975094 -0.025289 0.195344 0.884435 1.000000 0.974701 0.970772
y 0.951722 -0.029341 0.183760 0.865421 0.974701 1.000000 0.952006
z 0.953387 0.094924 0.150929 0.861249 0.970772 0.952006 1.000000
相関係数を可視化する
相関係数の数字を表で見てもわかりにくいので、ヒートマップを使って可視化します。ヒートマップの描画にはseabornのheatmap()関数を使用します。
import pandas as pd
import seaborn as sns
df = sns.load_dataset('diamonds')
sns.heatmap(df.corr(), vmin=-1, vmax=1)
plt.show()
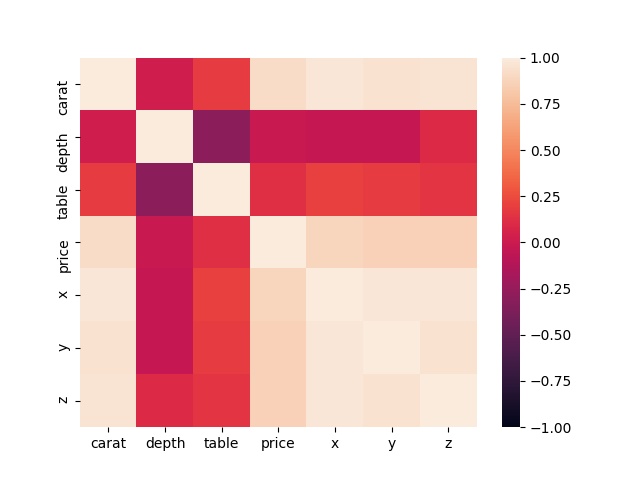
こうしてみると、priceと相関が強そうな項目がわかりますね。
主な関数やメソッド
DataFrame.corr()
DataFrameの各列間の欠損値を除いた相関係数を計算します。
ret = df.corr([method], [min_periods])
変数 |
型 |
内容 |
|---|---|---|
df |
DataFrame |
相関係数を計算するDataFrame。 |
method |
str |
省略可。既定値はpearson。相関係数の計算方法の指定。 |
min_periods |
int |
省略可。既定値は1。 |
ret |
DataFrame |
各項の相関係数を示すマトリクス。 |
DataFrameの型がobjectの列については、相関係数の計算は行われません。
method引数にpearsonを指定するとピアソンの相関係数が、kendallを指定するとケンドールの順位相関係数が、spearmanを指定するとスピアマンの順位相関係数が計算されます。
seaborn.heatmap()
ヒートマップを描画します。
import seaborn as sns
sns.heatmap(data, [vmin], [vmax], [cmap], [center], [robust], [annot], [fmt], [annot_kws], [linewidths], [linecolor], [cbar], [cbar_kws], [cbar_ax], [square], [xticklabels], [yticklabels], [mask], [ax])
変数 |
型 |
内容 |
|---|---|---|
data |
dataset |
ヒートマップを描画するマトリクス状のデータ。DataFrameなど。 |
vmin |
float |
省略可。既定値はNone。カラーマップの表示に用いる最小値。 |
vmax |
float |
省略可。既定値はNone。カラーマップの表示に用いる最大値。 |
cmap |
list |
省略可。既定値はNone。データとカラースペースの紐付け。 |
center |
float |
省略可。既定値はNone。カラーマップのセンターの値。 |
robust |
bool |
省略可。既定値はFalse。 |
annot |
dataset |
省略可。既定値はNone。 |
fmt |
str |
省略可。既定値は.2g。 |
annot_kws |
dict |
省略可。既定値はNone。 |
linewidths |
float |
省略可。既定値は0。各セル間の線の幅。 |
linecolor |
color |
省略可。既定値はwhite。各セル間の線の色。 |
cbar |
bool |
省略可。既定値はTrue。カラーバーを表示するかどうか。 |
cbar_kws |
dict |
省略可。既定値はNone。カラーバーの表示オプション。 |
cbar_ax |
Axes |
省略可。既定値はNone。カラーバーを描画するAxesの指定。 |
square |
bool |
省略可。既定値はFalse。 |
xticklabels |
list |
省略可。既定値はauto。 |
yticklabels |
list |
省略可。既定値はauto。 |
mask |
DataFrame |
省略可。既定値はNone。 |
ax |
Axes |
省略可。既定値はNone。描画するAxesの指定。Noneの場合はアクティブなAxesに描画。 |
公開日
広告
Pythonでデータ分析カテゴリの投稿
- DataFrameの欠損値を特定の値で置き換える
- Pythonでpandas入門1(データの入力とデータへのアクセス)
- Pythonでpandas入門2(データの追加と削除および並び替え)
- Pythonでpandas入門3(データの統計量の計算)
- Pythonでpandas入門4(データの連結と結合)
- Pythonでpandas入門5(欠損値(NaN)の扱い)
- Pythonでデータを学習用と検証用に分割する
- Pythonでデータ分析入門1(初めての回帰分析)
- Pythonでデータ分析入門2(初めてのロジスティック回帰(2クラス分類))
- Pythonでデータ分析入門3(初めての決定木(多クラス分類))
- Pythonで回帰モデルの評価関数
- Pythonで箱ひげ図を描く
- Python(pandas)でExcelファイルを読み込んでDataFrameにする
- pandasでカテゴリ変数を数値データに変換する
- pandasでクロス集計する
- pandasで同じデータ(要素)がいくつあるか調べる
- pandasで相関係数を計算する
- pandasとseabornでデータの可視化(散布図行列)
- pandasの学習用のデータセットを入手する
- scikit-learnのサンプルデータセットを入手する