Chainerのチュートリアルを試してみた(データ拡張編)
Chainerのチュートリアルを試してみました。今回はData augmentation(データ拡張)をしてみました。
目次
Data augmentation (データ拡張)とは
データに微小な変化を加えて学習データを増やすことで、学習の精度の向上を図るアイデアです。
今回はデータの数は増やしませんが、データそのものにランダムに変更を加えます。
具体的な方法としては、ChainerのTransformDatasetクラスを使います。このクラスは、データセットと変換の内容を定義した関数を与えると変換済みのデータセットオブジェクトを返してくれるという便利なクラスです。
コードは基本的には 以前の投稿 と同じく、CIFAR10を深いネットワークで分類するというものです。
実際のコード
変更したところを説明します。
chainer.datasetsからTransformDatasetをインポートします。
transformという関数を定義します。この関数がデータの変換の内容を表します。変換の中身は、ランダムにクロップすることと、50%の確率で反転することです。画像を表すデータと教師データのタプルを入力として受け取って、変換後の画像データと教師データのタプルを返します。
trainという学習部分の関数の中から、データを読み込む部分を削除します。これは、データ拡張を関数の外で行ってから関数に渡すようにしたためです。この関数の中でデータ拡張してもよかったのかな。
train関数を実行する直前にデータの読み込みとデータ拡張の実行を追加します。train関数を実行する際に引数に、学習用、検証用、テスト用の各データを指定します。
import pickle
import numpy
import random
import chainer
import chainer.cuda
import cupy
import chainer.links as L
import chainer.functions as F
from chainer import iterators
from chainer import optimizers
from chainer import training
from chainer.training import extensions
from chainer import serializers
from chainer.datasets import TransformDataset
# データ拡張の方法を定義する関数
def transform(inputs):
x, t = inputs
x = x.transpose(1, 2, 0)
h, w, _ = x.shape
x_offset = numpy.random.randint(4)
y_offset = numpy.random.randint(4)
x = x[y_offset:y_offset + h - 4,
x_offset:x_offset + w - 4] # ランダムクロップ
if numpy.random.rand() > 0.5:
x = numpy.fliplr(x)
x = x.transpose(2, 0, 1) # 反転
return x, t
# 畳み込み層部分の定義をするクラス
class ConvBlock(chainer.Chain):
def __init__(self, n_ch, pool_drop=False):
w = chainer.initializers.HeNormal()
super(ConvBlock, self).__init__()
with self.init_scope():
self.conv = L.Convolution2D(None, n_ch, 3, 1, 1, nobias=True, initialW=w) # 畳み込み層
self.bn = L.BatchNormalization(n_ch) # バッチノーマリゼーション層
self.pool_drop = pool_drop
def __call__(self, x):
h = F.relu(self.bn(self.conv(x))) # 入力を畳み込んで、バッチ正規化して、ReLUを通す
if self.pool_drop: # pool_dorpがTrueのときは、マックスプーリングして、ドロップアウトする
h = F.max_pooling_2d(h, 2, 2)
h = F.dropout(h, ratio=0.25)
return h
# 全結合層部分の定義をするクラス
class LinearBlock(chainer.Chain):
def __init__(self, drop=False):
w = chainer.initializers.HeNormal()
super(LinearBlock, self).__init__()
with self.init_scope():
self.fc = L.Linear(None, 1024, initialW=w) # 全結合層
self.drop = drop
def __call__(self, x):
h = F.relu(self.fc(x)) # 入力を全結合して、ReLuを通す
if self.drop: # dropがTrueのときは、ドロップアウトする
h = F.dropout(h)
return h
# ネットワーク全体の定義をするクラス
class DeepCNN(chainer.ChainList):
def __init__(self, n_output):
super(DeepCNN, self).__init__(
ConvBlock(64),
ConvBlock(64, True),
ConvBlock(128),
ConvBlock(128, True),
ConvBlock(256),
ConvBlock(256),
ConvBlock(256),
ConvBlock(256, True),
LinearBlock(),
LinearBlock(),
L.Linear(None, n_output)
)
def __call__(self, x):
for f in self:
x = f(x)
return x
# 学習を実行する関数
def train(network_object, batchsize=128, gpu_id=0, max_epoch=20, train_dataset=None, valid_dataset=None, test_dataset=None, postfix='', base_lr=0.01, lr_decay=None):
# 2. イテレーターの作成(データセットをバッチで取り出せるようにする)
train_iter = iterators.SerialIterator(train_dataset, batchsize)
valid_iter = iterators.SerialIterator(valid_dataset, batchsize, False, False)
# 3. ネットワークのインスタンスを作る
net = L.Classifier(network_object)
# 4. オプティマイザーの作成(学習量の計算の設定)
optimizer = optimizers.MomentumSGD(lr=base_lr).setup(net)
optimizer.add_hook(chainer.optimizer.WeightDecay(0.0005))
# 5. アップデーターの作成(ネットワークのパラメーターのアップデート)
updater = training.StandardUpdater(train_iter, optimizer, device=gpu_id)
# 6. トレーナーの作成(学習サイクルの実行)
trainer = training.Trainer(updater, (max_epoch, 'epoch'), out='{}_cifar10_{}result'.format(network_object.__class__.__name__, postfix))
# 7. トレーナーのオプションの設定
trainer.extend(extensions.LogReport())
trainer.extend(extensions.observe_lr())
trainer.extend(extensions.Evaluator(valid_iter, net, device=gpu_id), name='val')
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time', 'lr']))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
if lr_decay is not None:
trainer.extend(extensions.ExponentialShift('lr', 0.1), trigger=lr_decay)
trainer.run()
del trainer
# 8. 評価
test_iter = iterators.SerialIterator (test_dataset, batchsize, False, False)
test_evaluator = extensions.Evaluator(test_iter, net, device=gpu_id)
results = test_evaluator()
print('Test accuracy:', results['main/accuracy'])
return net
# 乱数を初期化する関数
def reset_seed(seed=0):
random.seed(seed)
numpy.random.seed(seed)
if chainer.cuda.available:
chainer.cuda.cupy.random.seed(seed)
# cuDNNのautotuneを有効にする
chainer.cuda.set_max_workspace_size(512 * 1024 * 1024)
chainer.config.autotune = True
# データセットの読み込み
with open('test.pickle', mode='rb') as fi1:
test_dataset = pickle.load(fi1)
with open('train.pickle', mode='rb') as fi2:
train_dataset = pickle.load(fi2)
with open('valid.pickle', mode='rb') as fi3:
valid_dataset = pickle.load(fi3)
# データの拡張
train_dataset = TransformDataset(train_dataset, transform)
# 学習の実行
net = train(DeepCNN(10), max_epoch=100, train_dataset=train_dataset, valid_dataset=valid_dataset, test_dataset=test_dataset, base_lr=0.1, lr_decay=(30, 'epoch'))
# 学習結果の保存
serializers.save_npz('my_cifar10.model', net)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time lr
1 2.45378 0.160756 2.06101 0.224805 20.1448 0.1
10 0.861467 0.702457 0.93969 0.673437 174.932 0.1
20 0.618317 0.792103 0.722736 0.761719 346.451 0.1
30 0.548754 0.816351 0.581285 0.807617 517.517 0.1
40 0.223793 0.922585 0.296265 0.905273 689.152 0.01
50 0.181405 0.936213 0.310319 0.903906 860.716 0.01
60 0.165184 0.942196 0.324293 0.905469 1032.85 0.01
70 0.0731503 0.974387 0.297377 0.921484 1205.14 0.001
80 0.0568122 0.980346 0.302277 0.922656 1376.94 0.001
90 0.0505237 0.982416 0.315913 0.916992 1548.91 0.001
100 0.0431994 0.985352 0.314449 0.917773 1721.9 0.0001
Test accuracy: 0.9193038
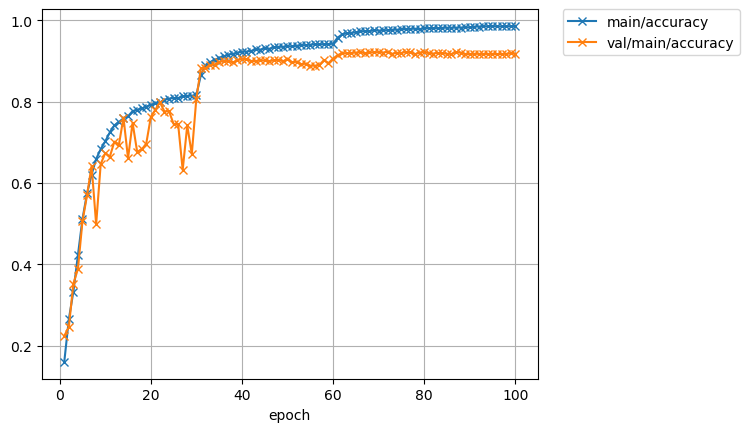
精度はおよそ92%になりました。2%の改善です。
では推論してみます。コードは 前の投稿 の推論プログラムのコードと同じです。
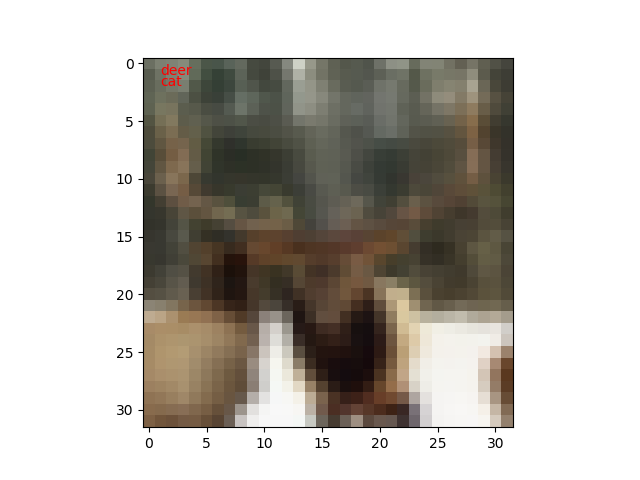
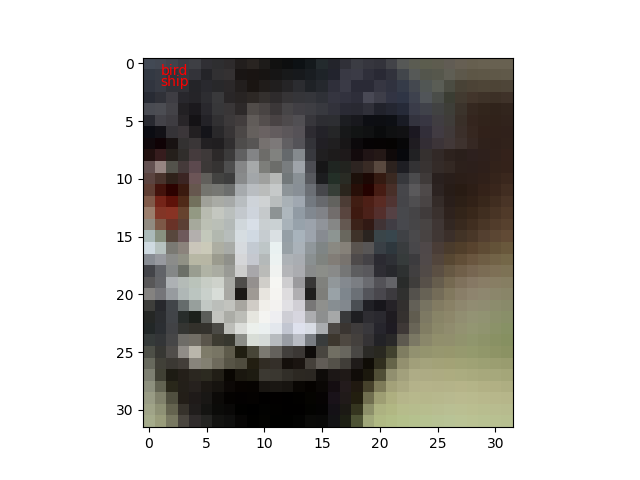
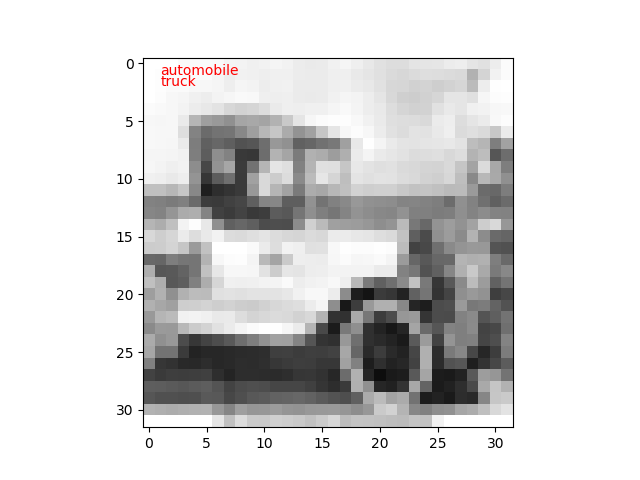
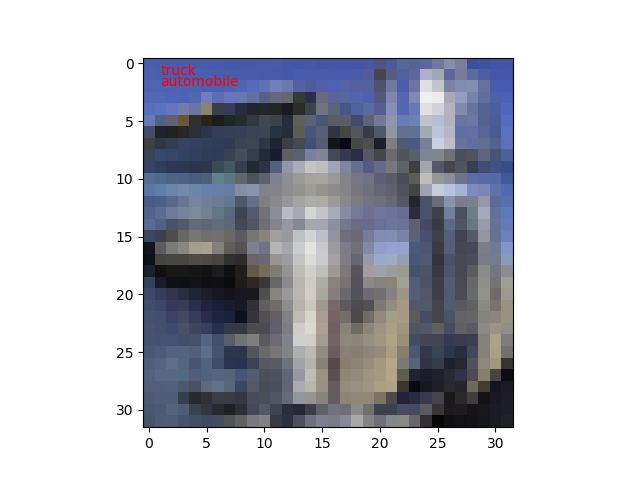
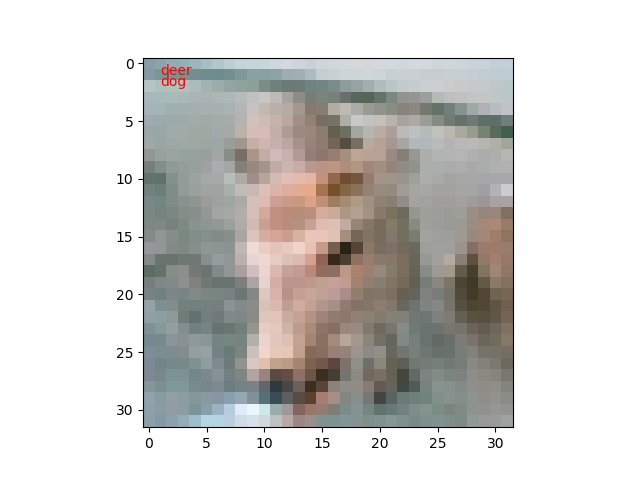
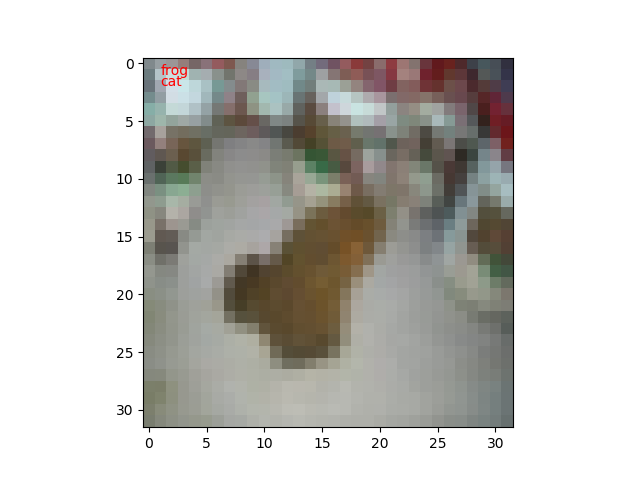
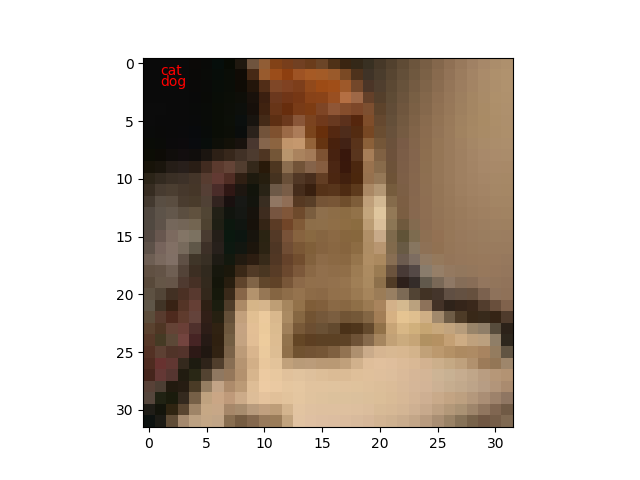
枚数が増えたのは100枚しか見てないから偶然なのだと思います。n=8/100なら正答率92%ですからね。
公開日
広告
Chainerカテゴリの投稿
- ChainerCVで使える画像のデータ拡張
- ChainerCVで画像を出力する方法
- ChainerCVのResNetを使う
- ChainerCVのSSDに学習させてみた
- ChainerCVのデモンストレーションプログラムを読んでみた
- ChainerCVのデモンストレーションプログラムを読んでみた(推論編)
- Chainerが出力するネットワーク構造図をGraphvizで見る
- Chainerで数字を分類してみた
- ChainerのSSDのデモで物体検出をしてみる
- Chainerのチュートリアルを試してみた
- Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
- Chainerのチュートリアルを試してみた(データ拡張編)
- Chainerのチュートリアルを試してみた(トレーナー編)
- Chainerのチュートリアルを試してみた(畳み込みを深くする編)
- Chainerのチュートリアルを試してみた(畳み込み編)
- Chainerのデータセットの作り方(ラベル付き画像編)
- VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた