Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
Chainerのチュートリアルを試してみました。今回はChainerCVを使ってData augmentation(データ拡張)をしてみました。
目次
ChainerCVとは
ChainerCV というのは、Chainerの画像関係の拡張ライブラリです。
pipでインストールできます。
> pip install chainercv
今回はCainerCVを使ってデータ拡張をしてみます。
データ拡張してみた
チュートリアルの内容は、 以前の投稿 と同じくCIFAR10の分類です。
変更したところは、主にデータの読み込みとデータ拡張のところです。学習の部分はそのまま流用します。
データの読み込みについては、読み込む際のオプションを変えて読み込んだデータの表現が0から1の少数ではなく0から255の整数になるようにしました。また、学習用とテスト用のデータの分割を学習用のスクリプトの方で行うようにしました。
import pickle
from chainer.datasets import cifar
# データセットのダウンロード
train_val, test_dataset = cifar.get_cifar10(scale=255.)
# データセットをローカルファイルに保存
with open('train_val.pickle', mode='wb') as fo1:
pickle.dump(train_val, fo1)
with open('test_dataset.pickle', mode='wb') as fo2:
pickle.dump(test_dataset, fo2)
データのダウンロードに意外と時間がかかるんですよね。
次に学習のコードです。
transformという名前の、データの拡張方法を定義する関数があります。この関数の中にどういう風にデータを拡張するかを書いて、TransformDatasetクラスに引数として渡します。
今回は、色味の変更と正規化とフリップ・拡張・クロップを行います。学習用と検証用とテスト用のすべてのデータに同じ関数を適用するのですが、正規化以外の拡張は学習用データのみに適用するようにしてあります。
transformsのメンバーにいろいろな変換が定義されててそのメンバーを呼べば変換してくれるから、変換の手続きをいちいち書かなくてよいのが楽でよいです。
ほかは基本的に以前のものを踏襲します。
import pickle
import numpy as np
import random
from functools import partial
from chainercv import transforms
import chainer
import chainer.cuda
import cupy
from chainer.datasets import split_dataset_random
from chainer.datasets import TransformDataset
import chainer.links as L
import chainer.functions as F
from chainer import iterators
from chainer import optimizers
from chainer import training
from chainer.training import extensions
from chainer import serializers
# データの拡張方法を定義する関数
def transform(inputs, train=True):
img, label = inputs
img = img.copy()
# 色味の変更
if train:
img = transforms.pca_lighting(img, 76.5)
# 正規化
img -= mean[:, None, None]
img /= std[:, None, None]
# ランダムにフリップ、拡張、クロップ
if train:
img = transforms.random_flip(img, x_random=True)
img = transforms.random_expand(img, max_ratio=1.5)
img = transforms.random_crop(img, (28, 28))
return img, label
# 畳み込み層部分の定義をするクラス
class ConvBlock(chainer.Chain):
def __init__(self, n_ch, pool_drop=False):
w = chainer.initializers.HeNormal()
super(ConvBlock, self).__init__()
with self.init_scope():
self.conv = L.Convolution2D(None, n_ch, 3, 1, 1, nobias=True, initialW=w) # 畳み込み層
self.bn = L.BatchNormalization(n_ch) # バッチノーマリゼーション層
self.pool_drop = pool_drop
def __call__(self, x):
h = F.relu(self.bn(self.conv(x))) # 入力を畳み込んで、バッチ正規化して、ReLUを通す
if self.pool_drop: # pool_dorpがTrueのときは、マックスプーリングして、ドロップアウトする
h = F.max_pooling_2d(h, 2, 2)
h = F.dropout(h, ratio=0.25)
return h
# 全結合層部分の定義をするクラス
class LinearBlock(chainer.Chain):
def __init__(self, drop=False):
w = chainer.initializers.HeNormal()
super(LinearBlock, self).__init__()
with self.init_scope():
self.fc = L.Linear(None, 1024, initialW=w) # 全結合層
self.drop = drop
def __call__(self, x):
h = F.relu(self.fc(x)) # 入力を全結合して、ReLuを通す
if self.drop: # dropがTrueのときは、ドロップアウトする
h = F.dropout(h)
return h
# ネットワーク全体の定義をするクラス
class DeepCNN(chainer.ChainList):
def __init__(self, n_output):
super(DeepCNN, self).__init__(
ConvBlock(64),
ConvBlock(64, True),
ConvBlock(128),
ConvBlock(128, True),
ConvBlock(256),
ConvBlock(256),
ConvBlock(256),
ConvBlock(256, True),
LinearBlock(),
LinearBlock(),
L.Linear(None, n_output)
)
def __call__(self, x):
for f in self:
x = f(x)
return x
# 学習を実行する関数
def train(network_object, batchsize=128, gpu_id=0, max_epoch=20, train_dataset=None, valid_dataset=None, test_dataset=None, postfix='', base_lr=0.01, lr_decay=None):
# 2. イテレーターの作成(データセットをバッチで取り出せるようにする)
train_iter = iterators.SerialIterator(train_dataset, batchsize)
valid_iter = iterators.SerialIterator(valid_dataset, batchsize, False, False)
# 3. ネットワークのインスタンスを作る
net = L.Classifier(network_object)
# 4. オプティマイザーの作成(学習量の計算の設定)
optimizer = optimizers.MomentumSGD(lr=base_lr).setup(net)
optimizer.add_hook(chainer.optimizer.WeightDecay(0.0005))
# 5. アップデーターの作成(ネットワークのパラメーターのアップデート)
updater = training.StandardUpdater(train_iter, optimizer, device=gpu_id)
# 6. トレーナーの作成(学習サイクルの実行)
trainer = training.Trainer(updater, (max_epoch, 'epoch'), out='{}_cifar10_{}result'.format(network_object.__class__.__name__, postfix))
# 7. トレーナーのオプションの設定
trainer.extend(extensions.LogReport())
trainer.extend(extensions.observe_lr())
trainer.extend(extensions.Evaluator(valid_iter, net, device=gpu_id), name='val')
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time', 'lr']))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
if lr_decay is not None:
trainer.extend(extensions.ExponentialShift('lr', 0.1), trigger=lr_decay)
trainer.run()
del trainer
# 8. 評価
test_iter = iterators.SerialIterator (test_dataset, batchsize, False, False)
test_evaluator = extensions.Evaluator(test_iter, net, device=gpu_id)
results = test_evaluator()
print('Test accuracy:', results['main/accuracy'])
return net
# 乱数を初期化する関数
def reset_seed(seed=0):
random.seed(seed)
np.random.seed(seed)
if chainer.cuda.available:
chainer.cuda.cupy.random.seed(seed)
reset_seed(0)
# データセットの読み込み
with open('train_val.pickle', mode='rb') as fi1:
train_val = pickle.load(fi1)
with open('test_dataset.pickle', mode='rb') as fi2:
test_dataset = pickle.load(fi2)
# データセットの分割
train_size = int(len(train_val) * 0.9)
train_dataset, valid_dataset = split_dataset_random(train_val, train_size, seed=0)
# データの平均と標準偏差を求める
mean = np.mean([x for x, _ in train_dataset], axis=(0, 2, 3))
std = np.std([x for x, _ in train_dataset], axis=(0, 2, 3))
# データ拡張の実行
train_dataset = TransformDataset(train_dataset, partial(transform, train=True))
valid_dataset = TransformDataset(valid_dataset, partial(transform, train=False))
test_dataset = TransformDataset(test_dataset, partial(transform, train=False))
# cuDNNのautotuneを有効にする
chainer.cuda.set_max_workspace_size(512 * 1024 * 1024)
chainer.config.autotune = True
# 学習の実行
net = train(DeepCNN(10), max_epoch=100, train_dataset=train_dataset, valid_dataset=valid_dataset, test_dataset=test_dataset, postfix='augmented2_', base_lr=0.1, lr_decay=(30, 'epoch'))
# 学習結果の保存
serializers.save_npz('my_cifar10.model', net)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time lr
1 2.57346 0.143044 2.15097 0.183789 22.2775 0.1
11 1.06216 0.634832 1.08398 0.641797 194.029 0.1
21 0.818134 0.726763 0.763982 0.752734 366.679 0.1
31 0.583482 0.80653 0.387201 0.870117 539.688 0.01
41 0.398289 0.862549 0.314873 0.894727 712.585 0.01
51 0.357748 0.87727 0.362336 0.891602 885.704 0.01
61 0.292896 0.89846 0.255397 0.921094 1058.46 0.001
71 0.230856 0.920028 0.253145 0.923437 1230.09 0.001
81 0.213539 0.925071 0.247323 0.926953 1403.2 0.001
91 0.194686 0.932151 0.242556 0.928711 1576.4 0.0001
100 0.191047 0.93315 0.244707 0.929297 1732.49 0.0001
Test accuracy: 0.92266613
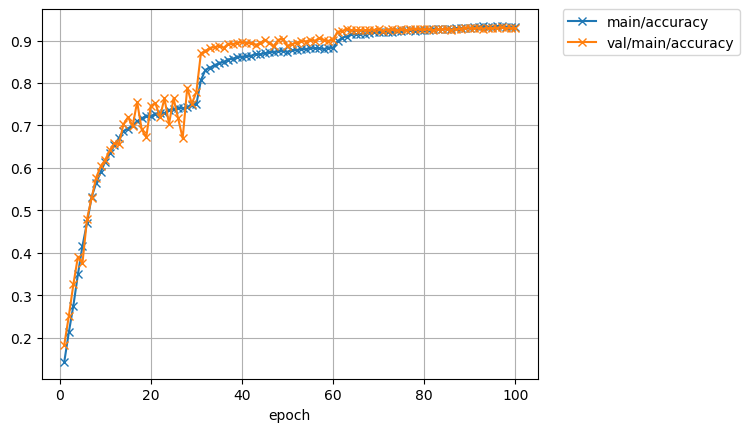
ちょっと精度が上がりました。
公開日
広告
Chainerカテゴリの投稿
- ChainerCVで使える画像のデータ拡張
- ChainerCVで画像を出力する方法
- ChainerCVのResNetを使う
- ChainerCVのSSDに学習させてみた
- ChainerCVのデモンストレーションプログラムを読んでみた
- ChainerCVのデモンストレーションプログラムを読んでみた(推論編)
- Chainerが出力するネットワーク構造図をGraphvizで見る
- Chainerで数字を分類してみた
- ChainerのSSDのデモで物体検出をしてみる
- Chainerのチュートリアルを試してみた
- Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
- Chainerのチュートリアルを試してみた(データ拡張編)
- Chainerのチュートリアルを試してみた(トレーナー編)
- Chainerのチュートリアルを試してみた(畳み込みを深くする編)
- Chainerのチュートリアルを試してみた(畳み込み編)
- Chainerのデータセットの作り方(ラベル付き画像編)
- VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた