VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた
Microsoftが公開しているVoTTという画像アノテーションツールがあります。このツールのPascal VOC形式の出力をChainerCVでデータセットとして読み込んでみました。
目次
Pascal VOC形式でやりとりできるはずが
本記事の環境はVoTT 2.1、Chainer 6.1、ChainerCV 0.13です。
Microsoftが公開している VoTT という画像アノテーションツールがあります。アノテーションツールというのは、画像のどこに何が映っているのか機械学習用に印を付けるツールです。
このツールの出力形式として、Pascal VOC形式というものがあります。Pascal VOCというのは、ディープラーニングにおける物体検出の性能指標として使われているデータセットです。
ChainerCV にはPascal VOCのデータセットを読み込む機能があります。ということは、VoTTでアノテーションしたデータセットをChainerCVで読み込むなんてことが可能・・・なはずです。
VoTTのPascal VOC出力をChainerCVで読むときの課題
Pascal VOC形式といっても解釈がいろいろあるようで、VoTTの出力をそのままChainerCVで読み込もうとするとエラーになります。
ChainerCVのVOCBboxDatasetクラスはPascal VOCのご本家データ用
ChainerCVでPascal VOC形式を読もうとするとまずVOCBboxDatasetクラスを使おうと考えると思います。ですが、VOCBboxDatasetは本当にPascal VOCのご本家のデータを使うことを前提に作られているようです。まあ、これはこれで間違いではないのです。
VoTTのバウンディングボックスの座標が小数
VoTTはアノテーションツールですので、物体の画像の中の座標が出力されます。その座標が、小数で出力されます。画像データはピクセルの集まりなんだから、そこは整数なのでは? まあ、どっちに丸めるかをユーザーに選択してもらうということなのでしょう。
ChainerCVのVOCBboxDatasetクラスはそこが整数であることが前提になっているので、エラーになります。
画像データの分類ファイルの出力
Pascal VOCデータセットの中のImageSetsディレクトリの下に、どの画像がトレーニング用でどの画像がバリデーション用かを一覧にしたテキストファイルが出力されます。この出力が合わないのです。
VoTTの方は、アノテーションした物体の種類毎にtrainとvalidを分けてテキストファイルとして出力します。ChainerCVのVOCBboxDatasetクラスは、物体の種類はおかまいなしにtrainとvalidを読み取りたいのです。まあ、ユーザー側で出力後に学習させたい物体の種類を取捨選択できるようにしたということなのでしょう。
分類ファイルの書式
上記の分類ファイルの書式ですが、VoTTの方はフルファイル名(拡張子も含む)と何らかの数字を並べて出力します。数字の方の意味はわかりません。
ChainerCVのVOCBboxDatasetの方は、拡張子が含まれていないファイル名だけが列挙されていることが前提になっています。このファイルの情報から、画像ファイルにアクセスするときは拡張子にjpgを、アノテーションデータにアクセスするときは拡張子にxmlを自動的に付加しています。なので、ChainerCVが「ファイルが無いんだけど?」というエラーを出力します。(実際には、cv2のndimエラーかPILのファイル不明のエラーが出ます。)
どうする?
とはいえ、ChainerCVにビルトインされている機能を使えた方が使い勝手はよかろうと思うわけです。
ということで、VOCBboxDatasetを継承したクラスを作って対処します。
自家製クラス
ChainerCVのVOCBboxDatasetを継承したクラスを作ります。
元のソースコードとほとんど同じで、_get_imageと_get_annotationsメソッドだけを少しだけ改変します。
import os
import xml.etree.ElementTree as ET
import numpy as np
from chainercv.datasets import VOCBboxDataset
from chainercv.utils import read_image
from my_bbox_label_name import voc_labels
class MyVoTTVOCDataset(VOCBboxDataset):
def _get_image(self, i):
id_ = self.ids[i]
# ファイルリストの後ろに数字が付いている場合と、拡張子の有り無しに対応
if ' ' in id_:
id_ = id_.split()[0]
id_, ext_ = os.path.splitext(id_)
if len(ext_) < 1:
ext_ = '.jpg'
# jpg以外の拡張子に対応
img_path = os.path.join(self.data_dir, 'JPEGImages', id_ + ext_)
img = read_image(img_path, color=True)
return img
def _get_annotations(self, i):
id_ = self.ids[i]
# ファイルリストの後ろに数字が付いている場合と、拡張子の有り無しに対応
if ' ' in id_:
id_ = id_.split()[0]
id_, ext_ = os.path.splitext(id_)
ext_ = '.xml'
# xmlの拡張子の有り無しに対応
anno = ET.parse(os.path.join(self.data_dir, 'Annotations', id_ + ext_))
bbox = []
label = []
difficult = []
for obj in anno.findall('object'):
bndbox_anno = obj.find('bndbox')
bbox.append([
# 小数の座標に対応
int(float(bndbox_anno.find(tag).text)) - 1
for tag in ('ymin', 'xmin', 'ymax', 'xmax')])
name = obj.find('name').text.lower().strip()
label.append(voc_labels.index(name))
bbox = np.stack(bbox).astype(np.float32)
label = np.stack(label).astype(np.int32)
difficult = np.array(difficult, dtype=np.bool)
return bbox, label, difficult
改変した箇所は、コメントが付いているところです。
変更内容はたいしたことないですね。
使用するときに、継承元のVOCBboxDatasetクラスの方から名前の指定が間違っていると警告が出ますが、動作に影響はないでしょう。
注意点
課題のところで紹介した分類用のテキストファイルについては、データセットクラスの外から指定するものなのでここでは対処できません。各テキストファイルを適宜マージするのが良いと思います。
使ってみる
実際に上記の自家製クラスを使ってみます。
my_bbox_label_name.py というファイルにラベルを定義しておきます。
voc_labels = ('ta', 'chainercv', 'deta', 'su')
これを自家製クラスとテストスクリプトでインポートします。
テストスクリプトはこんな感じです。
from matplotlib import pyplot as plt
from chainercv.visualizations import vis_bbox
from my_bbox_label_name import voc_labels
from my_vott_voc_dataset import MyVoTTVOCDataset
#クラスの動作チェック用
# データセットの読み込み
valid_dataset = MyVoTTVOCDataset('data/trial-PascalVOC-export', 'chainercv_train')
# データの表示
img, bbox, label = valid_dataset[0]
fig = plt.figure(figsize=(18,13.5), dpi=100)
ax = plt.subplot(1,1,1)
ax.set_axis_off()
ax.figure.tight_layout()
vis_bbox(img, bbox, label, label_names=voc_labels, ax=ax)
plt.show()
自家製クラスでデータセットの画像とアノテーションデータを読み込んで、ChainerCVのvis_bboxでイメージにして、matplotlibで出力するというものです。
VoTTでのアノテーションはこんな感じです。
実際に出力するとこうなります。
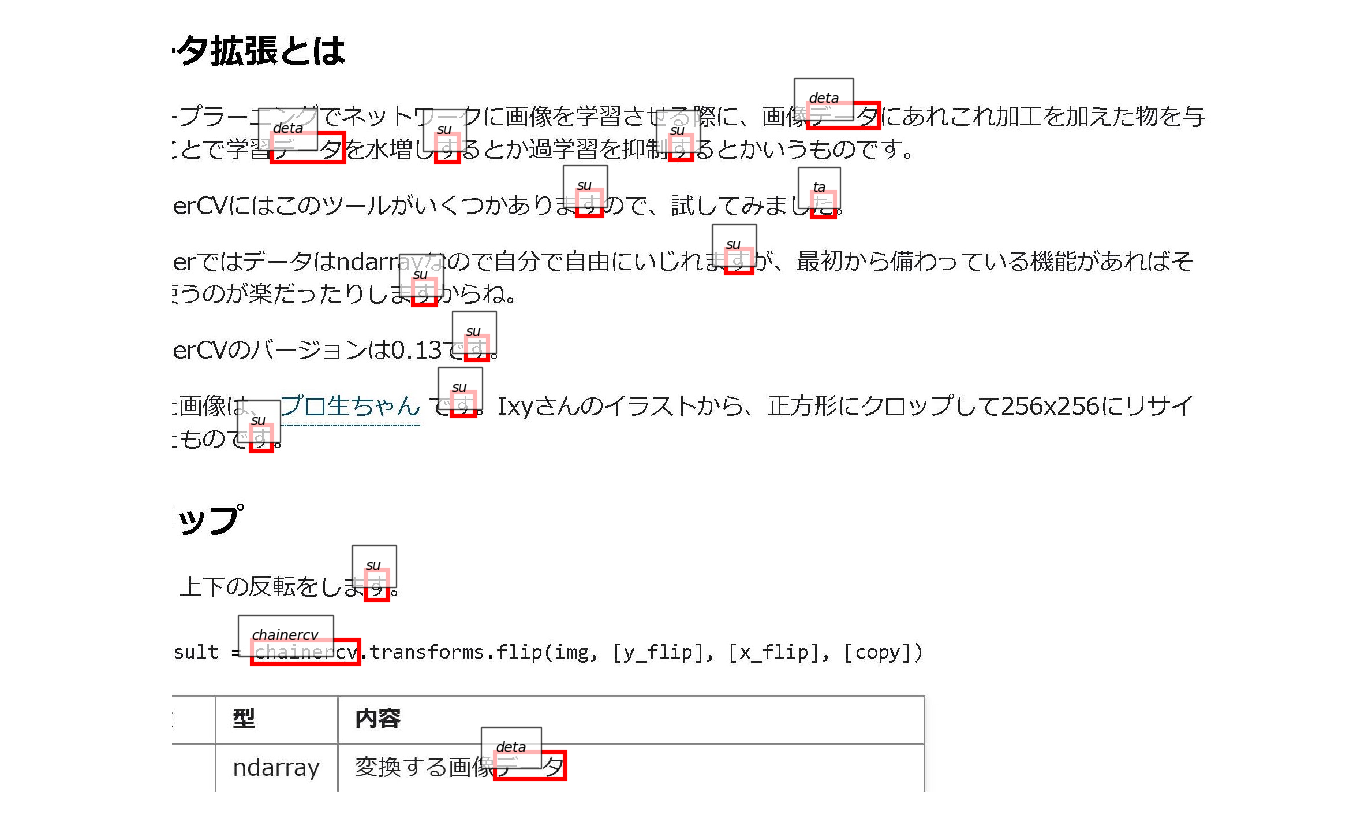
VoTTで付けたアノテーションが反映されてます。
公開日
広告
Chainerカテゴリの投稿
- ChainerCVで使える画像のデータ拡張
- ChainerCVで画像を出力する方法
- ChainerCVのResNetを使う
- ChainerCVのSSDに学習させてみた
- ChainerCVのデモンストレーションプログラムを読んでみた
- ChainerCVのデモンストレーションプログラムを読んでみた(推論編)
- Chainerが出力するネットワーク構造図をGraphvizで見る
- Chainerで数字を分類してみた
- ChainerのSSDのデモで物体検出をしてみる
- Chainerのチュートリアルを試してみた
- Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
- Chainerのチュートリアルを試してみた(データ拡張編)
- Chainerのチュートリアルを試してみた(トレーナー編)
- Chainerのチュートリアルを試してみた(畳み込みを深くする編)
- Chainerのチュートリアルを試してみた(畳み込み編)
- Chainerのデータセットの作り方(ラベル付き画像編)
- VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた