ChainerCVのSSDに学習させてみた
ChainerCVのSSDモデルを使って、画像から文字を検出してみました。
目次
画像から文字を抽出したい
ChainerCV にはSSD(Single Shot multibox Detector)という物体検出用のモデルが備わっています。これは、画像に描画されている物体を検出して識別するという便利なモデルです。
画像から物を検出するのですから文字だって検出できるよね、ということで試してみました。
学習データを作る
まずは学習データを作ります。データとしては、画像と、画像のどこに何があるかを示したデータが必要になります。こういうのをアノテーションデータと呼びますが、こういうデータを作るツールがいろいろあります。今回は、 VoTT(Visual Object Tagging Tool) というツールを使うことにしました。
このツールでPascal VOC形式の出力をして、その出力結果をChainerCVでデータセットとして読み込んで使います。読み込み方は 以前の投稿 を参考にしてください。
学習データの作成はこんな感じになります。
今回は、画像データからChainerという文字列を検出します。
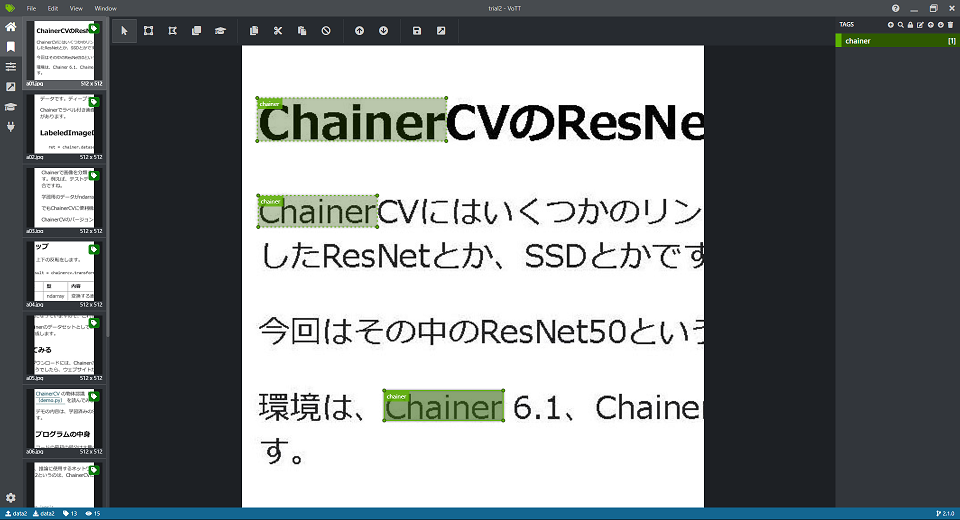
このようなデータを学習用に11枚、検証用に3枚作りました。枚数の中途半端さに意味はありません。
学習する
ではChainerに学習してもらいます。
コードは下記のようにしました。
import copy
import numpy as np
import chainer
from chainer.datasets import TransformDataset
from chainer.optimizer_hooks import WeightDecay
from chainer import serializers
from chainer import training
from chainer.training import extensions
from chainer.training import triggers
from chainercv.datasets import VOCBboxDataset
from chainercv.extensions import DetectionVOCEvaluator
from chainercv.links.model.ssd import GradientScaling
from chainercv.links.model.ssd import multibox_loss
from chainercv.links import SSD512
from chainercv import transforms
from chainercv.links.model.ssd import random_crop_with_bbox_constraints
from chainercv.links.model.ssd import random_distort
from chainercv.links.model.ssd import resize_with_random_interpolation
from my_vott_voc_dataset import MyVoTTVOCDataset
from my_bbox_label_name import voc_labels
import cv2
cv2.setNumThreads(0)
class MultiboxTrainChain(chainer.Chain):
def __init__(self, model, alpha=1, k=3):
super(MultiboxTrainChain, self).__init__()
with self.init_scope():
self.model = model
self.alpha = alpha
self.k = k
def forward(self, imgs, gt_mb_locs, gt_mb_labels):
mb_locs, mb_confs = self.model(imgs)
loc_loss, conf_loss = multibox_loss(mb_locs, mb_confs, gt_mb_locs, gt_mb_labels, self.k)
loss = loc_loss * self.alpha + conf_loss
chainer.reporter.report({'loss': loss, 'loss/loc': loc_loss, 'loss/conf': conf_loss}, self)
return loss
class Transform(object):
def __init__(self, coder, size, mean):
self.coder = copy.copy(coder)
self.coder.to_cpu()
self.size = size
self.mean = mean
def __call__(self, in_data):
img, bbox, label = in_data
img = random_distort(img)
if np.random.randint(2):
img, param = transforms.random_expand(img, fill=self.mean, return_param=True)
bbox = transforms.translate_bbox(bbox, y_offset=param['y_offset'], x_offset=param['x_offset'])
img, param = random_crop_with_bbox_constraints(img, bbox, return_param=True)
bbox, param = transforms.crop_bbox(bbox, y_slice=param['y_slice'], x_slice=param['x_slice'], allow_outside_center=False, return_param=True)
label = label[param['index']]
_, H, W = img.shape
img = resize_with_random_interpolation(img, (self.size, self.size))
bbox = transforms.resize_bbox(bbox, (H, W), (self.size, self.size))
img, params = transforms.random_flip(img, x_random=True, return_param=True)
bbox = transforms.flip_bbox(bbox, (self.size, self.size), x_flip=params['x_flip'])
img -= self.mean
mb_loc, mb_label = self.coder.encode(bbox, label)
return img, mb_loc, mb_label
def main():
# cuDNNのautotuneを有効にする
chainer.cuda.set_max_workspace_size(512 * 1024 * 1024)
chainer.config.autotune = True
gpu_id = 0
batchsize = 6
out_num = 'results'
log_interval = 1, 'epoch'
epoch_max = 500
initial_lr = 0.0001
lr_decay_rate = 0.1
lr_decay_timing = [200, 300, 400]
# モデルの設定
model = SSD512(n_fg_class=len(voc_labels), pretrained_model='imagenet')
model.use_preset('evaluate')
train_chain = MultiboxTrainChain(model)
# GPUの設定
chainer.cuda.get_device_from_id(gpu_id).use()
model.to_gpu()
# データセットの設定
train_dataset = MyVoTTVOCDataset('data2/trial2-PascalVOC-export', 'chainer_train')
valid_dataset = MyVoTTVOCDataset('data2/trial2-PascalVOC-export', 'chainer_val')
# データ拡張
transformed_train_dataset = TransformDataset(train_dataset, Transform(model.coder, model.insize, model.mean))
# イテレーターの設定
train_iter = chainer.iterators.MultiprocessIterator(transformed_train_dataset, batchsize)
valid_iter = chainer.iterators.SerialIterator(valid_dataset, batchsize, repeat=False, shuffle=False)
# オプティマイザーの設定
optimizer = chainer.optimizers.MomentumSGD()
optimizer.setup(train_chain)
for param in train_chain.params():
if param.name == 'b':
param.update_rule.add_hook(GradientScaling(2))
else:
param.update_rule.add_hook(WeightDecay(0.0005))
# アップデーターの設定
updater = training.updaters.StandardUpdater(train_iter, optimizer, device=gpu_id)
# トレーナーの設定
trainer = training.Trainer(updater, (epoch_max, 'epoch'), out_num)
trainer.extend(extensions.ExponentialShift('lr', lr_decay_rate, init=initial_lr), trigger=triggers.ManualScheduleTrigger(lr_decay_timing, 'epoch'))
trainer.extend(DetectionVOCEvaluator(valid_iter, model, use_07_metric=False, label_names=voc_labels), trigger=(1, 'epoch'))
trainer.extend(extensions.LogReport(trigger=log_interval))
trainer.extend(extensions.observe_lr(), trigger=log_interval)
trainer.extend(extensions.PrintReport(['epoch', 'iteration', 'lr', 'main/loss', 'main/loss/loc', 'main/loss/conf', 'validation/main/map', 'elapsed_time']), trigger=log_interval)
if extensions.PlotReport.available():
trainer.extend(
extensions.PlotReport(
['main/loss', 'main/loss/loc', 'main/loss/conf'],
'epoch', file_name='loss.png'))
trainer.extend(
extensions.PlotReport(
['validation/main/map'],
'epoch', file_name='accuracy.png'))
trainer.extend(extensions.snapshot(filename='snapshot_epoch_{.updater.epoch}.npz'), trigger=(10, 'epoch'))
# 途中で止めた学習を再開する場合は、trainerにスナップショットをロードして再開する
# serializers.load_npz('results/snapshot_epoch_100.npz', trainer)
# 学習実行
trainer.run()
# 学習データの保存
model.to_cpu()
serializers.save_npz('my_ssd_model.npz', model)
if __name__ == '__main__':
main()
GPUを使わないととても計算できないです。
データセットの設定のところで、自家製のクラスを使用しています。これについては 以前の投稿 を参考にしてください。
10エポック毎にスナップショットを保存するようになっています。スナップショットから学習状況を再現して学習を再開するには、serializers.load_npzでスナップショットをトレーナーを対象にしてロードします。
あとはコード内のコメントの通りで、特別なことはないと思います。
学習開始時の学習率が高すぎると、ロスの計算結果がnanになったりします。
学習結果
では、精度とロスの経過を見てみましょう。最終的な精度は83%ほどでした。
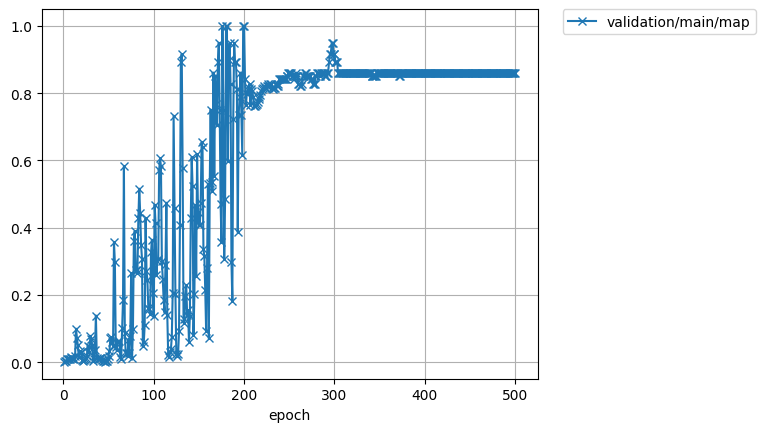
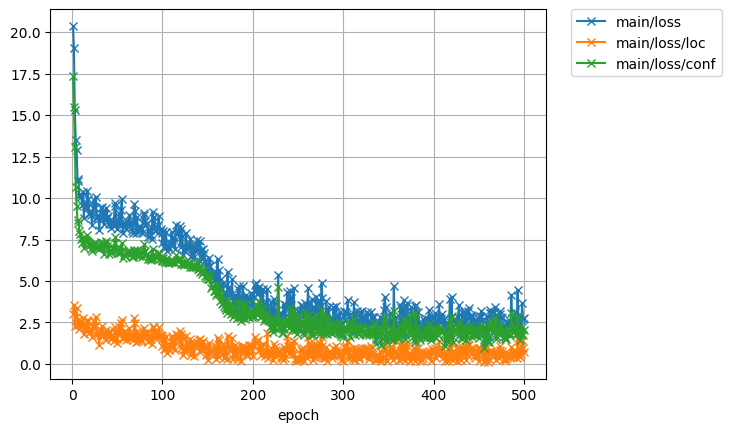
200エポック目と400エポック目で、学習率を1/10に変化させています。ただ、学習率の変化は学習の進展にはあまり寄与していなさそうです。安定はしてますが。
150エポックのあたりで急激にロスが減ってますね。データを増やすとこのタイミングがもう少し早くなるのかな。
推論してみた
ではこの学習結果を使って推論をしてみます。
推論のコードはこのようにしました。
from chainercv.links import SSD512
from chainer import serializers
from chainercv.visualizations import vis_bbox
from chainercv import utils
from matplotlib import pyplot as plt
from my_bbox_label_name import voc_labels
def inference(image_filename):
img = utils.read_image(image_filename, color=True)
bboxes, labels, scores = model.predict([img])
bbox, label, score = bboxes[0], labels[0], scores[0]
fig = plt.figure(figsize=(5.12,5.12), dpi=100)
ax = plt.subplot(1,1,1)
ax.set_axis_off()
ax.figure.tight_layout()
vis_bbox(img, bbox, label, label_names=voc_labels, ax=ax)
plt.show()
model = SSD512(n_fg_class=len(voc_labels))
serializers.load_npz('my_ssd_model.npz', model)
inference('data2/trial2-PascalVOC-export/JPEGImages/a01.jpg')
それでは実際に推論した結果をいくつか見てみましょう。



まずまず検出できてますね。8個中7個検出してますから、87%くらいかな。
注意点
今回使ったモデルはSSD512です。SSD300よりも小さい物体の検出に向いているモデルではあるのですが、それでも小さい物体の検出は苦手です。
例えばA5サイズに10ポイントで書いた文字を検出するというのは、SSD512では難しいです。(実際に一度失敗しました。)
公開日
広告
Chainerカテゴリの投稿
- ChainerCVで使える画像のデータ拡張
- ChainerCVで画像を出力する方法
- ChainerCVのResNetを使う
- ChainerCVのSSDに学習させてみた
- ChainerCVのデモンストレーションプログラムを読んでみた
- ChainerCVのデモンストレーションプログラムを読んでみた(推論編)
- Chainerが出力するネットワーク構造図をGraphvizで見る
- Chainerで数字を分類してみた
- ChainerのSSDのデモで物体検出をしてみる
- Chainerのチュートリアルを試してみた
- Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
- Chainerのチュートリアルを試してみた(データ拡張編)
- Chainerのチュートリアルを試してみた(トレーナー編)
- Chainerのチュートリアルを試してみた(畳み込みを深くする編)
- Chainerのチュートリアルを試してみた(畳み込み編)
- Chainerのデータセットの作り方(ラベル付き画像編)
- VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた