ChainerCVのResNetを使う
ChainerCVに備わっているResNetというネットワークを使ってみました。
目次
ChainerCVのResNet
ChainerCVにはいくつかのリンク(ネットワーク)が予め備わっています。例えばVGGとか、今回使用したResNetとか、SSDとかです。
今回はその中のResNet50というネットワークを使って、MNISTの画像分類をしてみました。
環境は、Chainer 6.1、ChainerCV 0.13、CUDA 10.1です。GPUがないととてつもなく時間がかかります。
データセットの準備
自前のデータセットを読み込む練習として、Chainerの便利機能でダウンロードしたMNISTのデータを、PNGに変換してローカルに保存するようにしてみました。
import os
from PIL import Image, ImageOps
import chainer
def convert_to_png(dataset_object, data_name):
num_of_data = len(dataset_object)
index_string = ''
os.mkdir(data_name)
# 画像を1枚ずつ出力する
for data_counter in range(num_of_data):
image_data, label_data = dataset_object[data_counter]
# PillowのImageオブジェクトを作って、そのオブジェクトの画素をMNISTの画像に合わせて書き換える
img = Image.new('L', (28,28))
pix = img.load()
for i in range(28):
for j in range(28):
pix[i, j] = int(image_data[i+j*28]*256)
# 画像の書き出し
file_name = data_name + '/' + str(data_counter) + '.png'
img.save(file_name)
index_string = index_string + file_name + ' ' + str(label_data) + '\n'
# 画像ファイルとラベルの関係データの書き出し
with open('index_' + data_name + '.txt', mode='wt', encoding='utf-8') as f:
f.write(index_string)
# MNISTのデータの読み込み
train, test = chainer.datasets.get_mnist()
# 実行
convert_to_png(train, 'train')
convert_to_png(test, 'test')
学習する
ResNet50に学習させます。
公式のサンプルを見ながら書きましたので、いまいち内容を理解できていないところがあります。追々勉強していこう。
import numpy as np
import chainer
from chainer import datasets
from chainer.datasets import LabeledImageDataset
from chainer.datasets import split_dataset_random
from chainer.links import Classifier
from chainercv.links.model.resnet import Bottleneck
from chainercv.links import ResNet50
from chainer.iterators import MultiprocessIterator
from chainer.iterators import SerialIterator
from chainer.optimizer import WeightDecay
from chainer.optimizers import MomentumSGD
from chainer.training import extensions
from chainer.training import StandardUpdater
from chainer.training import Trainer
from chainer import serializers
import cv2 # MaltiprocessIteratorがcv2を必要とするため、cv2をインポート
cv2.setNumThreads(0)
def main():
gpu_id = 0
max_epoch = 10
batchsize = 128
lr = 0.1
label_names = ['0','1','2','3','4','5','6','7','8','9']
# データセットの読み込み
train_val = LabeledImageDataset('index_train.txt')
test_dataset = LabeledImageDataset('index_test.txt')
# 平均画像の計算
mean_data = np.zeros((3, 28, 28))
for img, _ in train_val:
mean_data += img
mean_data = mean_data / float(len(train_val))
# 学習用データを学習用と検証用に分割する
train_size = int(len(train_val) * 0.9)
train_data, val_data = split_dataset_random(train_val, train_size, seed=0)
# モデルの定義
extractor = ResNet50(n_class=len(label_names), mean=mean_data)
extractor.pick = 'fc6'
model = Classifier(extractor)
for l in model.links():
if isinstance(l, Bottleneck):
l.conv3.bn.gamma.data[:] = 0
# 学習用イテレーターの設定
train_iter = MultiprocessIterator(train_data, batchsize)
val_iter = MultiprocessIterator(val_data, batchsize, repeat=False, shuffle=False)
# オプティマイザーの設定
optimizer = MomentumSGD(lr=lr).setup(model)
weight_decay = 0.0005
for param in model.params():
if param.name not in ('beta', 'gamma'):
param.update_rule.add_hook(WeightDecay(weight_decay))
# アップデーターの設定
updater = StandardUpdater(train_iter, optimizer, device=gpu_id)
# トレーナーの設定
trainer = Trainer(updater, (max_epoch, 'epoch'), out='result')
lr_decay = 30, 'epoch'
trainer.extend(extensions.LogReport())
trainer.extend(extensions.observe_lr())
trainer.extend(extensions.Evaluator(val_iter, model, device=gpu_id), name='val')
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time', 'lr']))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
if lr_decay is not None:
trainer.extend(extensions.ExponentialShift('lr', 0.1), trigger=lr_decay)
# cuDNNのautotuneを有効にする
chainer.cuda.set_max_workspace_size(512 * 1024 * 1024)
chainer.config.autotune = True
# モデルをGPUへ送る
if gpu_id >= 0:
chainer.cuda.get_device(gpu_id).use()
model.to_gpu()
# 学習を実行
trainer.run()
# 評価
test_iter = SerialIterator(test_dataset, batchsize, False, False)
test_evaluator = extensions.Evaluator(test_iter, model, device=gpu_id)
results = test_evaluator()
print('Test accuracy:', results['main/accuracy'])
# 学習結果の保存
model.to_cpu()
serializers.save_npz('my_resnet.model', model)
if __name__ == '__main__':
main()
イテレーターのくだり以降は、チュートリアルなどと同じ流れだと思います。ResNetをどうやって使うのか、具体的な実装方法にえらく悩みました。皆さんはどこで使い方を覚えるのでしょう。
画像が小さいので、バッチサイズが128でも使用メモリは2GB以下でした。GTX1050でも動くと思います。実行時間はGTX1060で1エポックあたり約40秒弱です。
精度は98%まで上がりました。
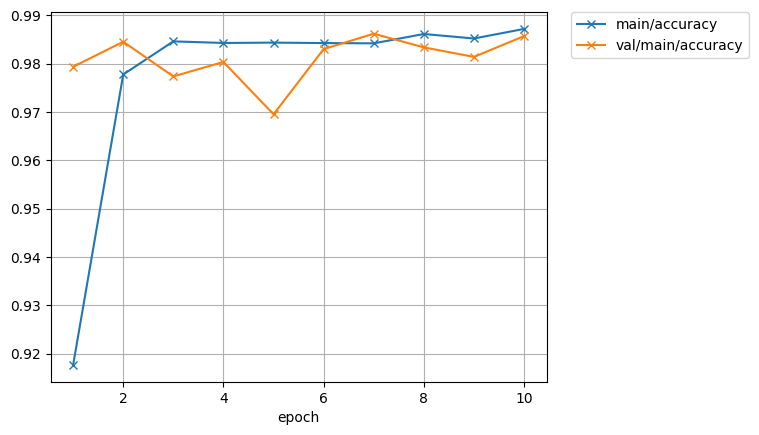
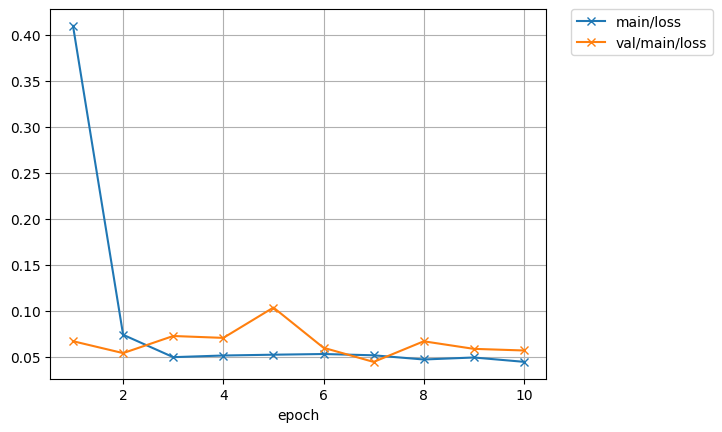
データに対してモデルが過剰ですね。
推論する
学習したら推論してみます。推論が動かなかったら意味がないですからね。
import chainer
from chainer.datasets import LabeledImageDataset
from chainer.serializers import load_npz
from chainer.links import Classifier
from chainercv.links import ResNet50
from chainercv.utils import write_image
# データセットの読み込み
test_dataset = LabeledImageDataset('index_test.txt')
label_names = ['0','1','2','3','4','5','6','7','8','9']
# ネットワークのインスタンスを作る
extractor = ResNet50(n_class=10)
extractor.pick = 'fc6'
model = Classifier(extractor)
load_npz('./my_resnet.model', model)
# テストデータに対して推論を実行
result_list = []
for i in range(500):
x, t = test_dataset[i]
with chainer.using_config('train', False), chainer.using_config('enable_backprop', False):
y = model.predictor(x[None, ...]).data.argmax(axis=1)[0]
if label_names[t] != label_names[y]:
print(str(i) + ' label : ' + label_names[t] + '. predict : ' + label_names[y])
write_image(x, 'out'+str(i)+'.png')
result_list.append(str(i)+','+label_names[t]+','+label_names[y])
out_text = '\n'.join(result_list)
with open('test_result.txt', mode='wt', encoding='utf-8') as fo:
fo.write(out_text)
テスト用データのうち最初の500枚を推論して、教師データと推論の結果が異なるものを画像として出力し、そのリストをテキストファイルとして出力します。
ではどういう間違いをしたのか見てみましょう。
正解 9, 推論結果 5
正解 3, 推論結果 2

正解 4, 推論結果 6
正解 9, 推論結果 7

正解 6, 推論結果 0

正解 3, 推論結果 5

正解 8, 推論結果 0

公開日
広告
Chainerカテゴリの投稿
- ChainerCVで使える画像のデータ拡張
- ChainerCVで画像を出力する方法
- ChainerCVのResNetを使う
- ChainerCVのSSDに学習させてみた
- ChainerCVのデモンストレーションプログラムを読んでみた
- ChainerCVのデモンストレーションプログラムを読んでみた(推論編)
- Chainerが出力するネットワーク構造図をGraphvizで見る
- Chainerで数字を分類してみた
- ChainerのSSDのデモで物体検出をしてみる
- Chainerのチュートリアルを試してみた
- Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
- Chainerのチュートリアルを試してみた(データ拡張編)
- Chainerのチュートリアルを試してみた(トレーナー編)
- Chainerのチュートリアルを試してみた(畳み込みを深くする編)
- Chainerのチュートリアルを試してみた(畳み込み編)
- Chainerのデータセットの作り方(ラベル付き画像編)
- VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた