Chainerのチュートリアルを試してみた(畳み込み編)
Chainerのチュートリアルを試してみました。畳み込み層を持つネットワークを作って、CIFAR10というデータセットの分類をします。
目次
チュートリアルの内容
Chainerのチュートリアルは本家でも公開されてますが、今回試してみたのは こちらのサイトのもの です。リンク先のサイトではJupyter notebookを使う前提で書かれているのですが、本投稿ではローカル環境でのPythonで実行します。
環境は、Windows10 64bit、Python 3.7、Chainer 6.1です。GPUは使用しません。
CIFAR10とは
32x32サイズのカラー画像に10種類のラベルが付いたデータセットです。詳しくはウィキペディアを・・・と思ったのですが、日本語版には項目が無いようですので 英語の方をどうぞ 。
データセットのダウンロード
CIFAR10のデータセットは32x32と小さいとはいえ60,000枚分の画像データの集まりです。それなりに大きいデータですのでダウンロードに時間がかかりますし、何度もダウンロードしたら先方に申し訳ない気がします。
ということで、Chainerの便利機能でデータセットをダウンロードしたら、まずそのデータをローカルに保存することにします。また、この段階でデータを学習用と検証用に分割してしまいます。
import pickle
from chainer.datasets import cifar
from chainer.datasets import split_dataset_random
# データセットのダウンロード
train_val, test = cifar.get_cifar10()
train_size = int(len(train_val) * 0.9)
train, valid = split_dataset_random(train_val, train_size, seed=0)
# データセットをローカルファイルに保存
with open('train.pickle', mode='wb') as fo1:
pickle.dump(train, fo1)
with open('test.pickle', mode='wb') as fo2:
pickle.dump(test, fo2)
with open('valid.pickle', mode='wb') as fo3:
pickle.dump(valid, fo3)
ダウンロードしたデータを表示してみる
データセットの保存がうまくいったかどうか確認するために、ダウンロードしたデータを表示してみます。
import pickle
import matplotlib.pyplot as plt
# ローカルファイルからデータセットを読み込む
with open('test.pickle', mode='rb') as fi1:
test = pickle.load(fi1)
with open('train.pickle', mode='rb') as fi2:
train = pickle.load(fi2)
with open('valid.pickle', mode='rb') as fi3:
valid = pickle.load(fi3)
cls_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
x, t = test[0]
plt.imshow(x.transpose(1, 2, 0))
plt.text(1,1, cls_names[t], color='white')
plt.show()
x, t = train[0]
plt.imshow(x.transpose(1, 2, 0))
plt.text(1,1, cls_names[t], color='white')
plt.show()
x, t = valid[0]
plt.imshow(x.transpose(1, 2, 0))
plt.text(1,1, cls_names[t], color='white')
plt.show()
各データセットの1枚目の画像が表示されます。
学習してみる
ChainerのTrainerを使用します。おおまかに言って、次のような流れになります。
ネットワークを定義するクラスを作成する。
データセットを読み込む。
イテレーター(データからバッチを取り出す機能)を設定する。
ネットワークのインスタンスを作る。
オプティマイザー(パラメータを最適化する機能)を設定する。
アップデーター(パラメータを更新する機能)を設定する。
トレーナーを設定する。
学習の実行。
学習結果の保存。
GPUを使用しませんので、gpu idの設定は全て-1にします。
マルチプロセス用のイテレーターを設定するとパイプエラーになりましたので、シリアルイテレーターを使用します。
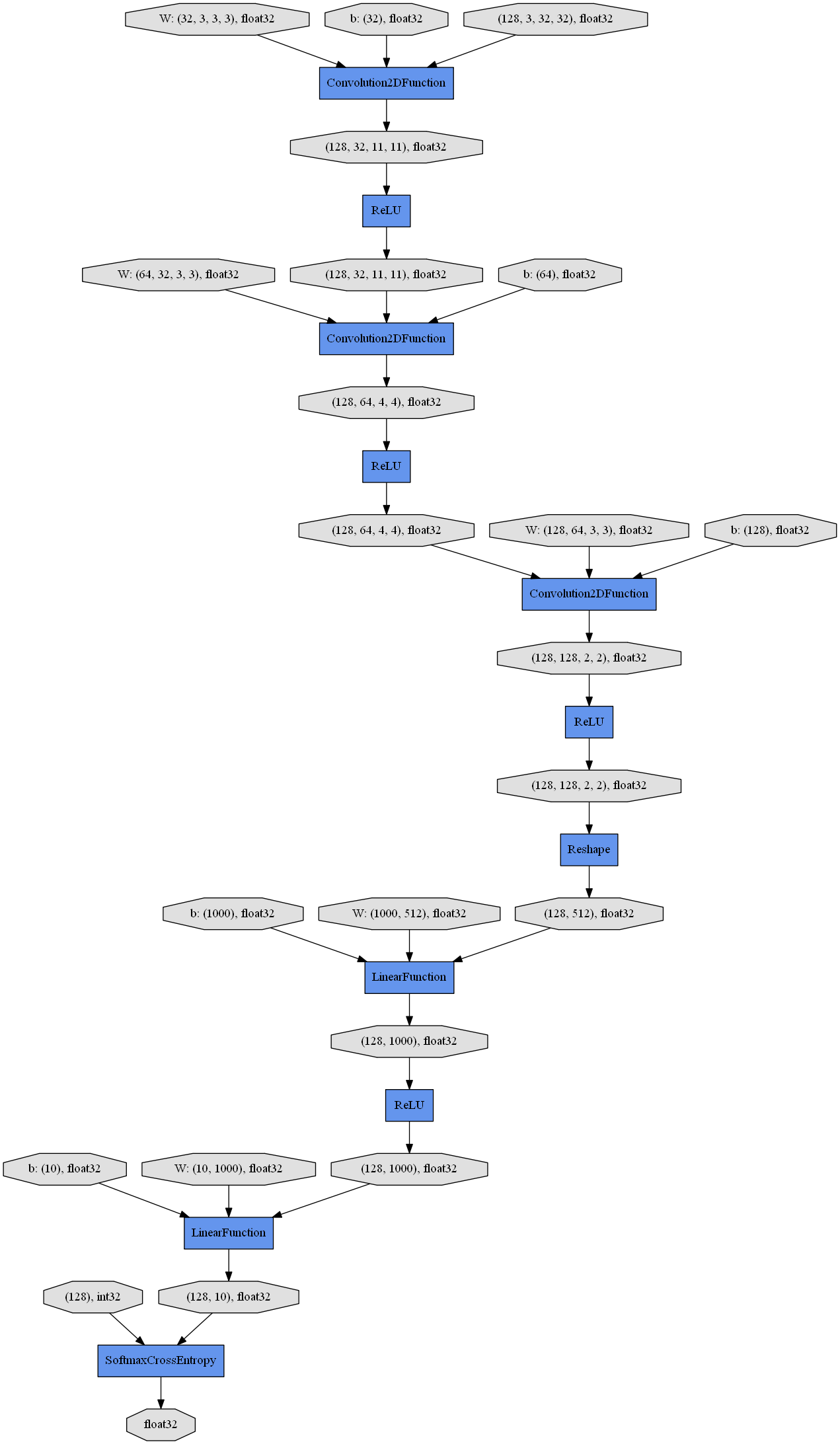
ネットワークはMyNetというChainを継承したクラスに定義します。今回は畳み込み層が3つと全結合層が2つで活性化関数がReLUのネットワークです。
import pickle
import numpy
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import iterators
from chainer import optimizers
from chainer import training
from chainer.training import extensions
from chainer import serializers
# ネットワークを定義するクラス
class MyNet(chainer.Chain):
def __init__(self, n_out):
super(MyNet, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(None, 32, 3, 3, 1)
self.conv2 = L.Convolution2D(32, 64, 3, 3, 1)
self.conv3 = L.Convolution2D(64, 128, 3, 3, 1)
self.fc4 = L.Linear(None, 1000)
self.fc5 = L.Linear(1000, n_out)
def __call__(self, x):
h = F.relu(self.conv1(x))
h = F.relu(self.conv2(h))
h = F.relu(self.conv3(h))
h = F.relu(self.fc4(h))
h = self.fc5(h)
return h
# 学習を実行する関数
def train(network_object, batchsize=128, gpu_id=-1, max_epoch=20, train_dataset=None, valid_dataset=None, test_dataset=None, postfix='', base_lr=0.01, lr_decay=None):
# 1. データセットの読み込み
with open('test.pickle', mode='rb') as fi1:
test = pickle.load(fi1)
with open('train.pickle', mode='rb') as fi2:
train = pickle.load(fi2)
with open('valid.pickle', mode='rb') as fi3:
valid = pickle.load(fi3)
# 2. イテレーターの作成(データセットをバッチで取り出せるようにする)
train_iter = iterators.SerialIterator(train, batchsize)
valid_iter = iterators.SerialIterator(valid, batchsize, False, False)
# 3. ネットワークのインスタンスを作る
net = L.Classifier(network_object)
# 4. オプティマイザーの作成(学習量の計算の設定)
optimizer = optimizers.MomentumSGD(lr=base_lr).setup(net)
optimizer.add_hook(chainer.optimizer.WeightDecay(0.0005))
# 5. アップデーターの作成(ネットワークのパラメーターのアップデート)
updater = training.StandardUpdater(train_iter, optimizer, device=gpu_id)
# 6. トレーナーの作成(学習サイクルの実行)
trainer = training.Trainer(updater, (max_epoch, 'epoch'), out='{}_cifar10_{}result'.format(network_object.__class__.__name__, postfix))
# 7. トレーナーのオプションの設定
trainer.extend(extensions.LogReport())
trainer.extend(extensions.observe_lr())
trainer.extend(extensions.Evaluator(valid_iter, net, device=gpu_id), name='val')
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'val/main/loss', 'val/main/accuracy', 'elapsed_time', 'lr']))
trainer.extend(extensions.PlotReport(['main/loss', 'val/main/loss'], x_key='epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'val/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
if lr_decay is not None:
trainer.extend(extensions.ExponentialShift('lr', 0.1), trigger=lr_decay)
trainer.run()
del trainer
# 8. 評価
test_iter = iterators.SerialIterator (test, batchsize, False, False)
test_evaluator = extensions.Evaluator(test_iter, net, device=gpu_id)
results = test_evaluator()
print('Test accuracy:', results['main/accuracy'])
return net
# 学習の実行
net = train(MyNet(10), gpu_id=-1)
# 学習結果の保存
serializers.save_npz('my_cifar10.model', net)
epoch main/loss main/accuracy val/main/loss val/main/accuracy elapsed_time lr
1 1.98288 0.283691 1.74354 0.38457 38.0775 0.01
2 1.64367 0.412464 1.57679 0.445312 76.017 0.01
3 1.51817 0.456909 1.52344 0.458789 113.396 0.01
4 1.42542 0.48908 1.41821 0.503516 150.861 0.01
5 1.35586 0.516026 1.37037 0.517773 188.074 0.01
6 1.29589 0.536199 1.35632 0.516406 225.592 0.01
7 1.24247 0.558338 1.30507 0.532031 262.579 0.01
8 1.19329 0.574796 1.25275 0.55957 299.961 0.01
9 1.15157 0.59142 1.2491 0.560156 337.248 0.01
10 1.1034 0.60962 1.20413 0.572852 374.534 0.01
11 1.05373 0.627131 1.20443 0.570117 411.467 0.01
12 1.01734 0.641894 1.21303 0.572461 448.237 0.01
13 0.968318 0.659712 1.22165 0.565234 485.678 0.01
14 0.925186 0.67557 1.15028 0.603516 522.889 0.01
15 0.889002 0.687189 1.18071 0.58125 560.312 0.01
16 0.844611 0.703459 1.17019 0.588867 597.813 0.01
17 0.797378 0.720748 1.14938 0.603906 635.043 0.01
18 0.757451 0.7318 1.19554 0.593164 671.74 0.01
19 0.70678 0.75049 1.23569 0.588086 709.042 0.01
20 0.669401 0.764893 1.18749 0.603125 746.52 0.01
Test accuracy: 0.6038370253164557
20エポック終了して、精度は約60%でした。グラフにするとこうなります。
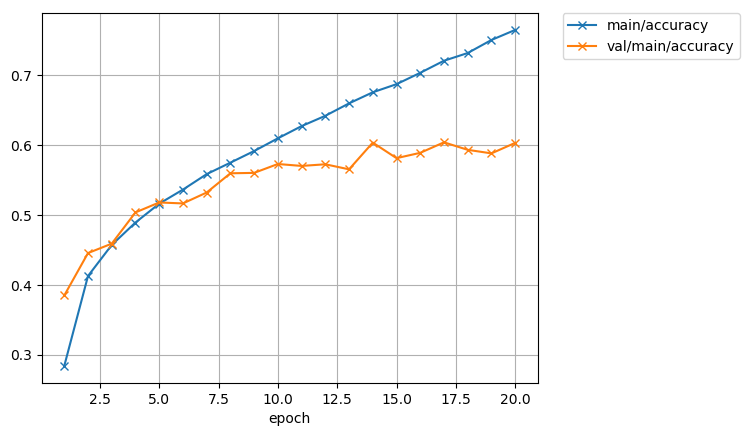
学習データでの精度は76%まで上がっているのに、検証データでの精度は8エポックのあたりから頭打ちになっています。ということは、学習に使ったデータだけが得意なネットワークになったということですね。
学習したネットワークで画像を分類してみる
学習したネットワークを使ってテスト用の画像データをいくつか分類してみます。流れとしてはこんな感じです。
ネットワークを定義する。
分類するデータの読み込み。
ネットワークの学習データの読み込み。
分類の実行。
表示。
ネットワークの定義自体は学習するときと同じです。
シリアライザーに学習データのファイルとネットワークのインスタンスを渡すと、学習データをネットワークに適用してくれます。
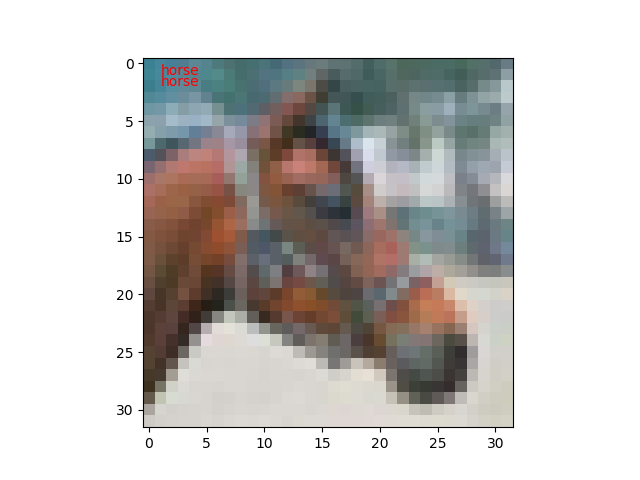
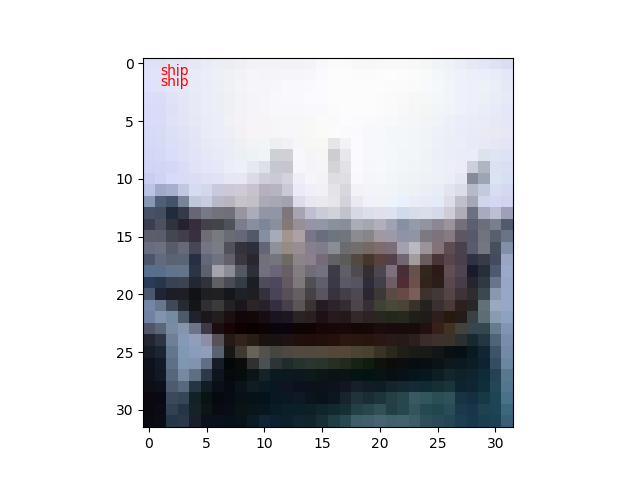
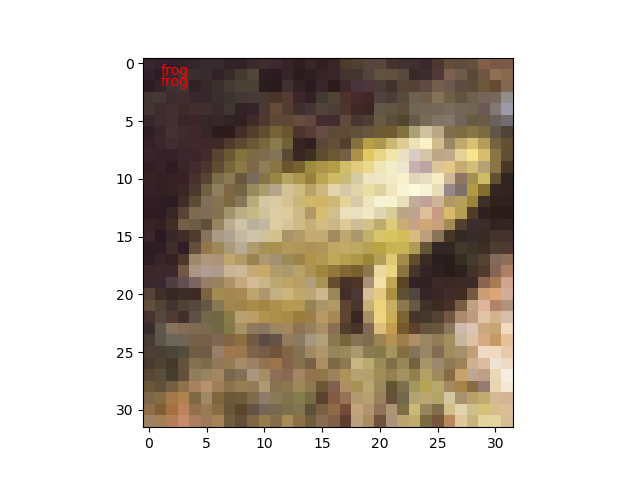
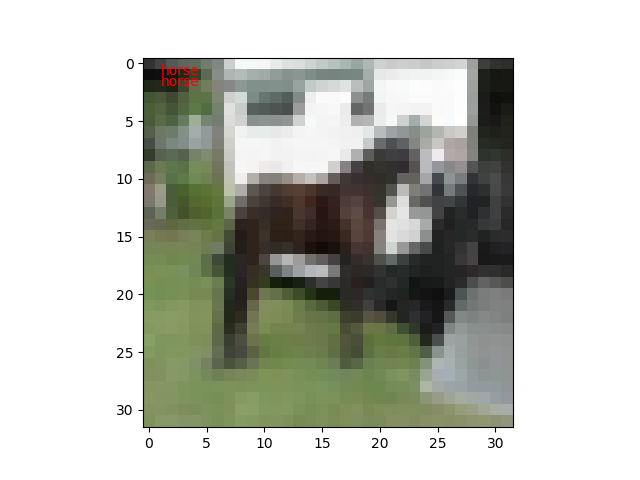
ネットワークのインスタンスのpredictorメソッドに分類用データを渡して、ラベルを判定してもらいます。
import pickle
import matplotlib.pyplot as plt
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import serializers
# ネットワークを定義するクラス
class MyNet(chainer.Chain):
def __init__(self, n_out):
super(MyNet, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(None, 32, 3, 3, 1)
self.conv2 = L.Convolution2D(32, 64, 3, 3, 1)
self.conv3 = L.Convolution2D(64, 128, 3, 3, 1)
self.fc4 = L.Linear(None, 1000)
self.fc5 = L.Linear(1000, n_out)
def __call__(self, x):
h = F.relu(self.conv1(x))
h = F.relu(self.conv2(h))
h = F.relu(self.conv3(h))
h = F.relu(self.fc4(h))
h = self.fc5(h)
return h
# 推論を実行する関数
def predict(net, image_id):
x, t = test[image_id]
with chainer.using_config('train', False), chainer.using_config('enable_backprop', False):
y = net.predictor(x[None, ...]).data.argmax(axis=1)[0]
plt.imshow(x.transpose(1, 2, 0))
plt.text(1,1, cls_names[t], color='red')
plt.text(1,2, cls_names[y], color='red')
plt.show()
# テストデータのラベル
cls_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
# テストデータの読み込み
with open('test.pickle', mode='rb') as fi1:
test = pickle.load(fi1)
# ネットワークのインスタンスの作成
infer_net = L.Classifier(MyNet(10))
# ネットワークの学習済みパラメーターの読み込み
serializers.load_npz('my_cifar10.model', infer_net)
# 推論の実行
for i in range(10, 15):
predict(infer_net, i)
試しに10枚ほど実行してみたところ、1枚だけ不正解でした。100枚もやれば正解率60%になるのでしょうけど。
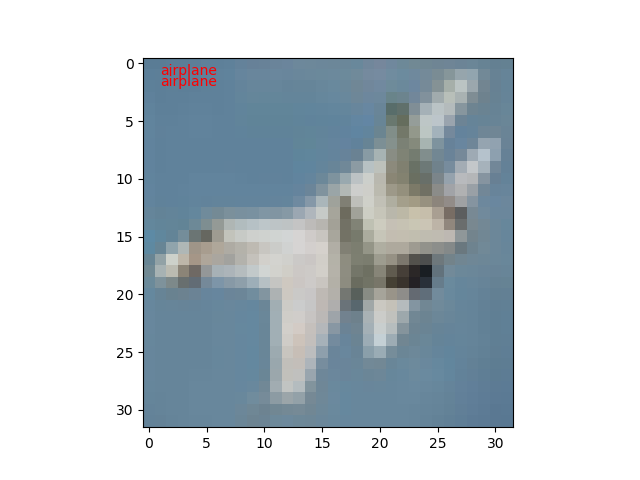




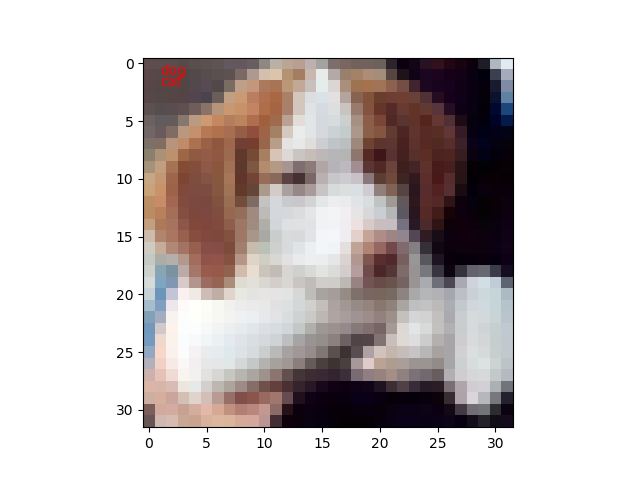
公開日
広告
Chainerカテゴリの投稿
- ChainerCVで使える画像のデータ拡張
- ChainerCVで画像を出力する方法
- ChainerCVのResNetを使う
- ChainerCVのSSDに学習させてみた
- ChainerCVのデモンストレーションプログラムを読んでみた
- ChainerCVのデモンストレーションプログラムを読んでみた(推論編)
- Chainerが出力するネットワーク構造図をGraphvizで見る
- Chainerで数字を分類してみた
- ChainerのSSDのデモで物体検出をしてみる
- Chainerのチュートリアルを試してみた
- Chainerのチュートリアルを試してみた(ChainerCVでデータ拡張編)
- Chainerのチュートリアルを試してみた(データ拡張編)
- Chainerのチュートリアルを試してみた(トレーナー編)
- Chainerのチュートリアルを試してみた(畳み込みを深くする編)
- Chainerのチュートリアルを試してみた(畳み込み編)
- Chainerのデータセットの作り方(ラベル付き画像編)
- VoTTのPascal VOC出力をChainerCVのデータセットとして読み込んでみた