MNISTの画像をPNGに変換してみた
ディープラーニングの例としてよく取り上げられるMNISTの画像データを、PNG形式に変換してみました。
目次
MNISTとは
ディープラーニングの学習で出てくる手書き文字の推論の例で使われるデータのセットです。28x28のグレイスケールの手書き数字の画像データが、ラベル付きで一塊になったものです。ネットワークの学習に使われるデータが60,000枚、検証に使用するデータが10,000枚のセットになっています。
データが一つの塊になっていますので、これをバラバラのPNG画像ファイルにしてみます。
また同時に、Chainerのデータセットとして扱いやすいように、画像ファイルとラベルの対応を示すテキストファイルも作成します。
早速分解してみる
MNISTデータのダウンロードには、Chainerの便利機能を使います。もし同じ機能で過去にダウンロードしたことがあるようでしたら、ウェブサイトからではなくそのローカルのデータを自動的に読み込みます。
import os
from PIL import Image, ImageOps
import chainer
def convert_to_png(dataset_object, data_name):
num_of_data = len(dataset_object)
index_string = ''
os.mkdir(data_name)
# 画像を1枚ずつ出力する
for data_counter in range(num_of_data):
image_data, label_data = dataset_object[data_counter]
# PillowのImageオブジェクトを作って、そのオブジェクトの画素をMNISTの画像に合わせて書き換える
img = Image.new('L', (28,28))
pix = img.load()
for i in range(28):
for j in range(28):
pix[i, j] = int(image_data[i+j*28]*256)
# 画像の白黒反転とリサイズ
img = ImageOps.invert(img)
img = img.resize((224,224), Image.BICUBIC)
# 画像の書き出し
file_name = data_name + '/' + str(data_counter) + '.png'
img.save(file_name)
index_string = index_string + file_name + ' ' + str(label_data) + '\n'
# 画像ファイルとラベルの関係データの書き出し
with open('index_' + data_name + '.txt', mode='wt', encoding='utf-8') as f:
f.write(index_string)
# MNISTのデータの読み込み
train, test = chainer.datasets.get_mnist()
# 実行
convert_to_png(train, 'train')
convert_to_png(test, 'test')
get_mnistメソッドで読み込んだデータセットは、訓練用と検証用のデータのタプルになっています。そのそれぞれがリストのような構造になっていて、各要素が画像を表す行列とラベルデータのタプルになっています。
ということで、データセットを読み込んだら最初に訓練用のデータ(train)と検証用のデータ(test)に分けます。そして、それぞれを画像データに分解していきます。
convert_to_pngという関数の中で、dataset_object[]というタプルをimage_dataとlabel_dataに分けています。
このimage_dataの型はndarrayになっています。28x28の画像を表すデータなのですが、2次元のマトリクスではなくて全ての列がつながった1次元の行列になっています。そこで、28x28のImageオブジェクトにループを使って各画素の値を当てはめていきます。256を掛けているのは、元のデータが0~1のfloat32なためです。
白黒反転とリサイズは、出力したデータの用途に合わせて加工したものです。
最後にテキストファイルを書き出していますが、これは出力した画像をChainerでデータセットとして扱う際に必要な物です。ファイルのパスとラベルを空白文字で区切って列挙したものです。
具体的にはこんな感じのファイルになります。
train/0.png 5
train/1.png 0
train/2.png 4
train/3.png 1
train/4.png 9
train/5.png 2
train/6.png 1
train/7.png 3
train/8.png 1
train/9.png 4
trainというフォルダの0.pngというファイルは、こんな感じになります。
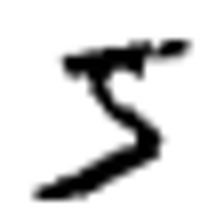
変換した画像をChainerで読み込んでみる
PNGに変換した画像データを、データセットとしてChainerで読み込んでみます。
具体的には、変換済みの画像をデータセットとして読んで、そのデータセットの中から1枚を再度画像に変換して出力してみます。
from chainer import datasets
from chainercv.utils import write_image
# データセットのインスタンスを作る
d = datasets.LabeledImageDataset('index_train.txt')
# 一つ目のデータを取り出す
image_data, label = d[0]
# 取り出したデータを画像として出力
write_image(image_data, 'out.png', format='png')
print(label)
Chainerのデータセットの形式はいくつかあるのですが、今回は LabeledImageDataset にしてみます。読んで字のごとく、ラベル付きの画像データセットですね。
このデータセットは、ファイルごとに1枚ずつ分かれた画像データと、画像ファイルのパスとラベルの関係を示すテキストファイルを組み合わせたものです。
D = chainer.datasets.LabeledImageDataset(pairs, [root], [dtype], [label_dtype])
変数 |
型 |
内容 |
|---|---|---|
pair |
str |
各画像ファイルのラベルを示すテキストファイルのパス。 |
root |
str |
省略可。規定値は./(作業フォルダ) |
dtype |
省略可。規定値はNone。 |
|
label_dtype |
省略可。規定値はNumpy.Int32。 |
|
D |
LabeledImageDataset |
データセットオブジェクト。 |
テキストファイルの書式は、画像ファイルのパス+スペース+ラベル(のインデックス数字)です。
前の項の出力例でいうと、カレントフォルダのtrainというサブフォルダがあり、そのサブフォルダの中に0.pngというファイルがあります。その画像ファイルのラベルは5です。(MNISTの場合は、ラベルの数字とインデックスになる数値が同じです。)
データセットの造りとしては、とても分かり易いですね。
公開日
広告