PythonでPDFファイルの文書情報の取得と書き換え
PyPDF2モジュールを使って、PDFファイルの文書情報(メタデータ)を取得したり書き換えたりしてみました。
目次
文書情報の読み取りの手順
PDFファイルには、文書として表示される情報の他に文書の著者などの情報(メタデータ)が入っています。こういった情報をPythonのPyPDF2モジュールを使って読み取ってみます。
PDFファイルのメタデータの格納方法は私の知る限りでは3種類あります。
Document Information Dictionary
Metadata stream
Extensible Metadata Platform (XMP)
Extensible Metadata Platform は、PDF 2.0以降で採用された方法です。
ここで読み取るメタデータは、Document Information Dictionary に格納されているデータです。
おおまかな手順は下記です。
PdfFileReaderでファイルを読み取る。
getDocumentInfoメソッドでDocumentInformationクラスのオブジェクトを作る。
DocumentInformationオブジェクトのプロパティにアクセスする。
情報取得に使用するクラスとメソッド
PdfFileReaderクラス
reader = PyPDF2.PdfFileReader(stream, [strict], [warndest], [overwriteWarnings])
名前 |
型 |
内容 |
|---|---|---|
stream |
PDFファイルのパスを示す文字列、またはreadとseekに対応したオブジェクト。 |
|
strict |
bool |
省略可。既定値はTrue。PDFファイルを読み取ったときの警告を表示するかどうか。 |
warndest |
省略可。既定値はsys.stderr。警告の出力先。 |
|
overwriteWarnings |
bool |
省略可。既定値はTrue。 |
reader |
PdfFileReaderオブジェクト。 |
PdfFileReaderオブジェクトを作成します。
getDocumentInfoメソッド
docinfo = reader.getDocumentInfo()
名前 |
型 |
内容 |
|---|---|---|
reader |
PdfFileReaderオブジェクト。 |
|
docinfo |
PDFファイルの文書情報を格納したDocumentInformationオブジェクト。 |
DocumentInformationオブジェクトを作成するメソッドです。Document Information Dictionaryにメタデータが無い場合は、Noneが返ります。
DocumentInformationクラス
下表のプロパティがあります。
プロパティ |
内容 |
|---|---|
author |
文書の著者。 |
author_raw |
|
creator |
文書の作成者。 |
creator_raw |
|
producer |
文書ファイルの生成ソフトウェア。 |
producer_raw |
|
subject |
文書の件名。 |
subject_raw |
|
title |
文書のタイトル。 |
title_raw |
戻り値の型は、TextStringObjectというUnicode文字列です。プロパティの最後がrawになっているものは、ByteStringObjectが返ってきます。値が設定されていないプロパティを参照した場合は、Noneが返ります。
これらのプロパティは読み込み専用で、プロパティに値をセットすることはできません。値を代入しようとするとエラーになります。
メタ情報の取得例
青空文庫からダウンロードした「こころ」のテキストをワードパッドに貼り付けて、PDFファイルとしてプリントしたものを作ります。このPDFファイルのメタデータを表示してみます。
ちなみに、AcrobatでこのPDFファイルのプロパティを表示させると、こんな感じになっています。

では、下記のコードでPDFファイルのプロパティを表示してみましょう。
import PyPDF2
with open('kokoro.pdf', mode='rb') as f:
reader = PyPDF2.PdfFileReader(f)
docinfo = reader.getDocumentInfo()
print(docinfo.title) # プロパティを指定する方法
for i in docinfo.keys():
print(i + '\t' + docinfo[i]) # 全てのプロパティを表示
タイトルを表示した後に、forループを使って全てのプロパティを表示させました。実行すると下記のようになります。
> python pdf_test.py
PdfReadWarning: Superfluous whitespace found in object header b'484' b'0' [pdf.py:1666]
kokoro.rtf
/Author xxxxxx
/CreationDate D:20200531094652+09'00'
/ModDate D:20200531094652+09'00'
/Producer Microsoft: Print To PDF
/Title kokoro.rtf
Authorのところは、おそらくWindowsのログイン名が入るのではないかと思います。
変換元がワードパッドなので、Titleがrtfファイルのファイル名になっています。
PDFに印刷したので、Print To PDFがProducerになってますね。
文書情報(メタデータ)の削除と書き換え
DocumentInformationオブジェクトのプロパティは読み込み専用なので、ダイレクトに書き換えはできません。しかし、新しく値をセットすることはできます。
そこで、メタデータをいったん削除してから新しく書き込むことで、書き換えを実現してみます。
DocumentInformationは辞書なので、popやdelでアイテムの削除ができます。
上でメタデータを読み取ったPDFファイルから、Producerを削除して、Authoerをfooに書き換えてみます。
書き換えに使用するクラスとメソッド
PdfFileWriterクラス
writer = PyPDF2.PdfFileWriter()
名前 |
型 |
内容 |
|---|---|---|
writer |
PdfFileWriterオブジェクト。 |
PdfFileWiterクラスは、ページオブジェクトをPDFファイルに書き込むためのクラスです。
cloneReaderDocumentRootメソッド
writer.cloneReaderDocumentRoot(reader)
名前 |
型 |
内容 |
|---|---|---|
writer |
PdfFileWriterオブジェクト。 |
|
reader |
コピー元となるPdfFileReaderオブジェクト。 |
PdfFileWriterオブジェクトにPdfFileReaderオブジェクトのドキュメントルートをコピーするメソッドです。
addMetadataメソッド
writer.addMetadata(infos)
名前 |
型 |
内容 |
|---|---|---|
writer |
PdfFileWriterオブジェクト。 |
|
infos |
dict |
メタデータのフィールド名をキーにした辞書。 |
PdfFileWriterオブジェクトにメタデータを書き込むメソッドです。引数はメタデータの辞書です。
writeメソッド
writer.write(stream)
名前 |
型 |
内容 |
|---|---|---|
writer |
PdfFileWriterオブジェクト。 |
|
stream |
ファイルオブジェクト、またはwriteとtellに対応したオブジェクト。 |
ファイルオブジェクトに書き込みをします。withおよびopenと共に使うのが良いでしょう。
メタ情報書き換えの実施例
では下記のコードで試してみます。
import PyPDF2
reader = PyPDF2.PdfFileReader('kokoro.pdf', strict=False)
docinfo = reader.getDocumentInfo()
# 元ファイルのメタデータの表示
for i in docinfo.keys():
print(i + '\t' + docinfo[i])
# メタデータを新しい辞書にコピー
modified_info = {k: docinfo[k] for k in docinfo.keys()}
# 書き出し用オブジェクトを生成して本体データをコピー
writer = PyPDF2.PdfFileWriter()
writer.cloneReaderDocumentRoot(reader)
# 辞書を加工してメタデータを書き込み
modified_info.pop('/Producer')
modified_info['/Author'] = 'foo'
writer.addMetadata(modified_info)
print('Modified meta data :')
for i in modified_info.keys():
print(i + '\t' + modified_info[i])
# PDFファイル出力
with open('out.pdf', mode='wb') as f:
writer.write(f)
出力はこうなります。
> python pdf_test.py
/Author xxxxxx
/CreationDate D:20200531094652+09'00'
/ModDate D:20200531094652+09'00'
/Producer Microsoft: Print To PDF
/Title kokoro.rtf
Modified meta data :
/Author foo
/CreationDate D:20200531094652+09'00'
/ModDate D:20200531094652+09'00'
/Title kokoro.rtf
出力されたPDFファイルのプロパティをAcrobatで表示してみるとこうなります。
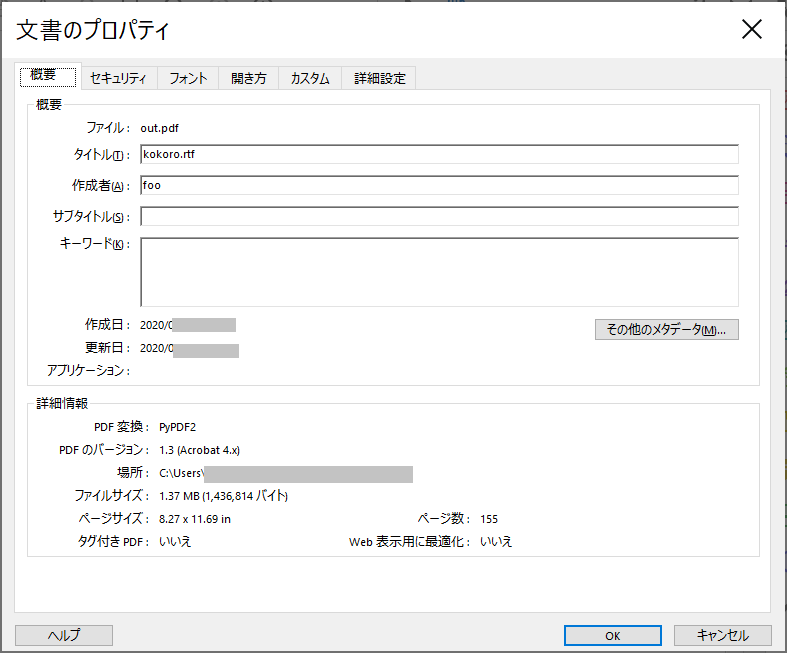
Authorは書き換わりました。
Titleは最初のままですね。
Producerは削除したのですが、PyPDF2になっています。Producerの指定をしないとPyPDF2が自動的に書き込まれるようですね。Producerを書き込まないようにしたい場合は、Producerを削除するのではなく、Producerに空の文字列を指定するとPyPDF2と書き込まれなくなります。
公開日
広告